Data uses and exports
Phontic and Phonology chart Export3
Based on the characters used in the flex database in the pronunciation field, or in an IPA based writing system in the lexeme field, a chart should be exportable so that an IPA chart is automatically propagated with the used characters. Other statistics should be easy enough to produce. Let me provide some examples.
IPA Consonat and Vowel Charts
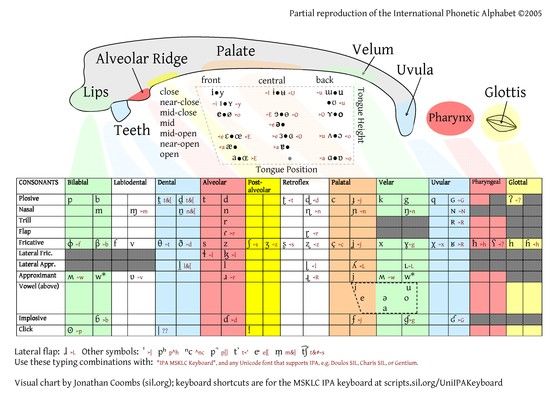
A consonant chart following the standard IPA chart with the sounds used in the language should be a standard exportable option such as is the case of the following chart of consonants for Indonesian.
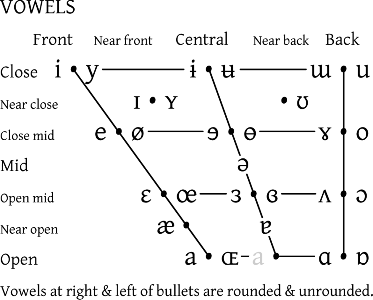
Then also a standard IPA vowel chart should be exportable based on the characters used.1
Word Melody charts for tone languages
This chart would output a list of the tonal melodies based on the grammar specifications (as pulled from the grammar analysis) of the word and its underlying lexical tonal melody2. The program would look at the tonal indication in the transcription method and then present a report. This report might look like the following:
Monosylabic Verbs (of syllable type x) in class 1
| Melodies | Low | Medium | High |
|---|---|---|---|
| N/A | yes | yes |
Monsylabic Verbs (of syllable type y) in class 2
| Melodies | Low | Medium | High |
|---|---|---|---|
| yes | N/A | yes |
Bisyllabic Verbs in class 1
| Melodies | Low-Low | Low-Medium | Low-High |
|---|---|---|---|
| N/A | yes | yes | |
| Medium-Low | Medium-medium | Medium-High | |
| yes | yes | yes | |
| High-Low | High-Medium | High-High | |
| N/A | yes | yes |
Bisyllabic Nouns in class 1
| Melodies | Low-Low | Low-Medium | Low-High |
|---|---|---|---|
| N/A | yes | yes | |
| Medium-Low | Medium-medium | Medium-High | |
| yes | yes | yes | |
| High-Low | High-Medium | High-High | |
| N/A | yes | yes |
Phonology charts
There is also a place for charts with phonological categories. Using the latest feature geometry model and the latest gestural models we can ascribe places based on characters used in the transcription system. An example is the phonology chart below describing Irish.
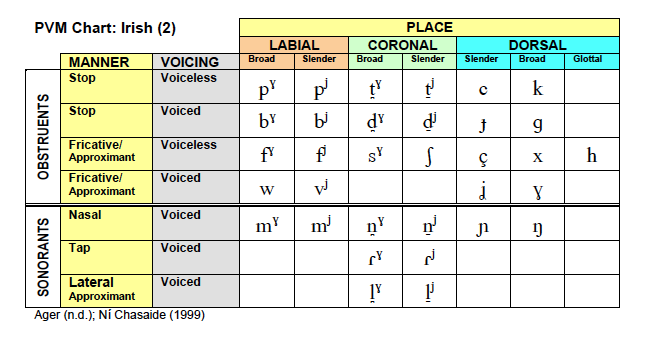
The second color based chart here would be very educational to have in digital publications but would be less useful in print based publications. Such a chart would also help people visualize how the feature based model analysis maps to articulation and pronunciation in a given language.
Syllable shape chart
Another phonetic chart is the syllable shape chart. This chart's producer will look at two things. The pronunciation field and the rules for syllabification This report should also automatically show which CV contexts and which type word contexts are used. Typologically we have STRENGTHS - CCCVCCC as perhaps the largest syllable globally. Syllable types should be an automatic report with the word they are contained in. These should also be related back to tonal melodies.
Orthography chart Export
This should export to XLingPaper with the phonological and technical information for making orthography statements. Much like the IPA sketch statements. (Elsewhere I have suggested that XLingPaper should have a template for orthography sketch which combines the information that Haskins, Moe, and others have suggested are necessary in an orthography sketch.)
Pronoun chart export
It would be fantastic if there were two pronoun chart exports.
One chart with all the kinds of pronouns.
One chart with all the pronouns of subject case, all the pronouns of object case, etc.
Body Part chart export
There should be several body part charts themed in the kinds of bodies from various areas of the world. These charts should be in SVG. FLEx’s XML export should be able to use XSLT to scan the whole lexicon for these body parts based on either English or semantic domain and then create a “draft” body part chart in SVG. Then s simple script should be able to convert the .svg to .png or .jpg.
Immediate and easy access to SIL’s repository of images
SIL has several collections of images which are CC licenses. These collections of images should be aligned to the semantic domain list and rapidly importable, and rapidly replaceable on a per-project bases.
Note: Both of these charts are not based on the phonetic values but rather the characters used in the transcription.
NA special dispensation would need to be made for
Contributions to Creative commons collections
In addition to easy access of images, SIL should make it very easy for image creators to modify an image and add it back to the collection or to add an image to SIL’s community collection under the creative commons license.
1. Both of these IPA charts are not based on phonetic values but rather the characteristics used in the transcription. It is possible that for those linguists who work with phonetic descriptions in Arabic linguistics and in Indic linguistics that another (other than IPA correspondence might need to be set up between characters used and the chart presentation). ↩
2. Tone is not super complicated, but many non-tonal linguists and many non-tonal language speakers are often befuddeld by it. Clear analysis in this presentation requires clear and consistent input. This short presentation does not even yet touch something like grammatical tone (and what one means by that), or surfae vs. underlying tone. These would all ideally be accounted for. ↩
3. Some of these described features are avaible under the auspices of SIL's Phonology Assistant, or CANIL's Dekekari. Both of these apps as companion apps are interesting and useful. However, I think their features need to be added as a plugin to the main database. This has the added benefit of allowing the plugin developers to focus on working within a framework, and not focusing on deploying an executable file. This also allows the users to have direct access across platforms to the features currently in those applications. ↩