Mexico Observations
My first experience with FLEx in a language documentation project was working in Mexico on Me'phaa. Me'phaa is a set of about nine languages which share a common writing system but spell words differently based on pronunciation. The major part of the speech community is from Gererro state Mexico. As with many language of Mexico Me'phaa speech varieties are tonal, and tone is indicated in their orthography. They also have nine regular inflections of each noun. However, these inflections use a type of fusional morphology, that the lead the principal investigator (PI), also a phonologist to an analysis point where he was un-willing to break apart the nominal morphemes to create the lexeme and an affixes. This meant we had a massive data entry problem for FLEx - each noun we encountered had a nine way option for inflection and we had nine languages under investigation. At the time another student and I both created a proposal for the FLEx team. This proposal has not really been acted upon (while this is sad, I am very, very delighted about the functionality of chorushub). These proposals are discussed later in this chapter.1
At the time I think we were working with FLEx 6 or FLEx 7. The PI wanted a data view of all varieties of Me'phaa to determine if a lexicon should be build for all the languages or for only one language at a time. Our set up looked like the following:
MicrosoftSQL Server for running FLEx on the Network. This is achieved through running XP in a virtual machine via Virtualbox on the OSX Server. We have multi-able entry points of data to the “FLEx System”. We also did not completely solve the network access to the data bases. That is one person could access the database at a time with write access. Since this project the current version of FLEx has moved from a MicrosoftSQL Server Backend to an XML backend. But perhaps what would have been better was to use FLExBridge or LiftBridge. But finding instructions on how to do this on OS X server at the time was impossible. So we had basically a virtual machine and tunnels into the database. Every team memeber (except Becky Paterson) was new to FLEx therefore FLEx actually got very little use.
Our work in Mexico caused us to file two requests for improvements to the application. With a proper login account these can be viewed at the listed links2.
Feature requests submitted
Request from the Meʼphaa Language Documentation team for Paradigm functionality in FLEx.
Authors
- Kevin Cline
- Hugh Paterson III
- Becky Paterson
- Steve Marlett
Date submitted to FLEx Dev Team
- 2 December 2010
Context
We are working from Mexico with (estimating) 9 varieties of Meʼphaa. These would include the languages which fall under the following ISO 639-3 codes: [tcf],[tpl],[tpx],[tpc]. We have a team of 4 trained SIL linguists. We are eliciting words in paradigms and comparing these paradigms across the varieties we are investigating.
Request
It would be very helpful if FLEx had some kind of functionality that would produce/display paradigms, especially for languages that seem to be more fusional or where morpheme breaks are not easily made (e.g., Me'phaa).
There are currently a few ways to go about doing this.
- The LIFT XML format currently allows for an entry to be tagged via range-sets as a variant with a "paradigm" trait with a given value (see the LIFT draft pp. 21 and 24). This method would appear to create sub-entries, having the benefit of keeping all the data together, but also making it hard for the data to be found by tools like the interlinear texts and Phonology Assistant. Flex currently does not support this method.
- The Flex help file has an article where it recommends using custom fields to define parts of a paradigm and bulk edits to enter the data. This seems somewhat clunky. And I think it would not be a great solution for paradigms with multiple inflections/entries (imagine verb paradigms for multiple tenses).
- There is a discussion on the FLEx list Google group ( http://groups.google.com/group/flex-list/browse_thread/thread/1a73bee176780212/9a4c131169af8c3d?q=paradigm&lnk=nl& ) which recommends using Inflectional Variants. One would define the possible variant forms in the Variant Types list and then add appropriate variants to a Main Entry through the Lexicon Edit tool. This method has the advantage that the variants/inflected forms are stored as separate entries, making them available to Phonology Assistant, etc. The main problem is that the entry is still tedious, and displaying each member of the paradigm together in a way that is helpful for analysis is difficult (they currently would appear in the main entry and possibly in a column in the Entries pane).
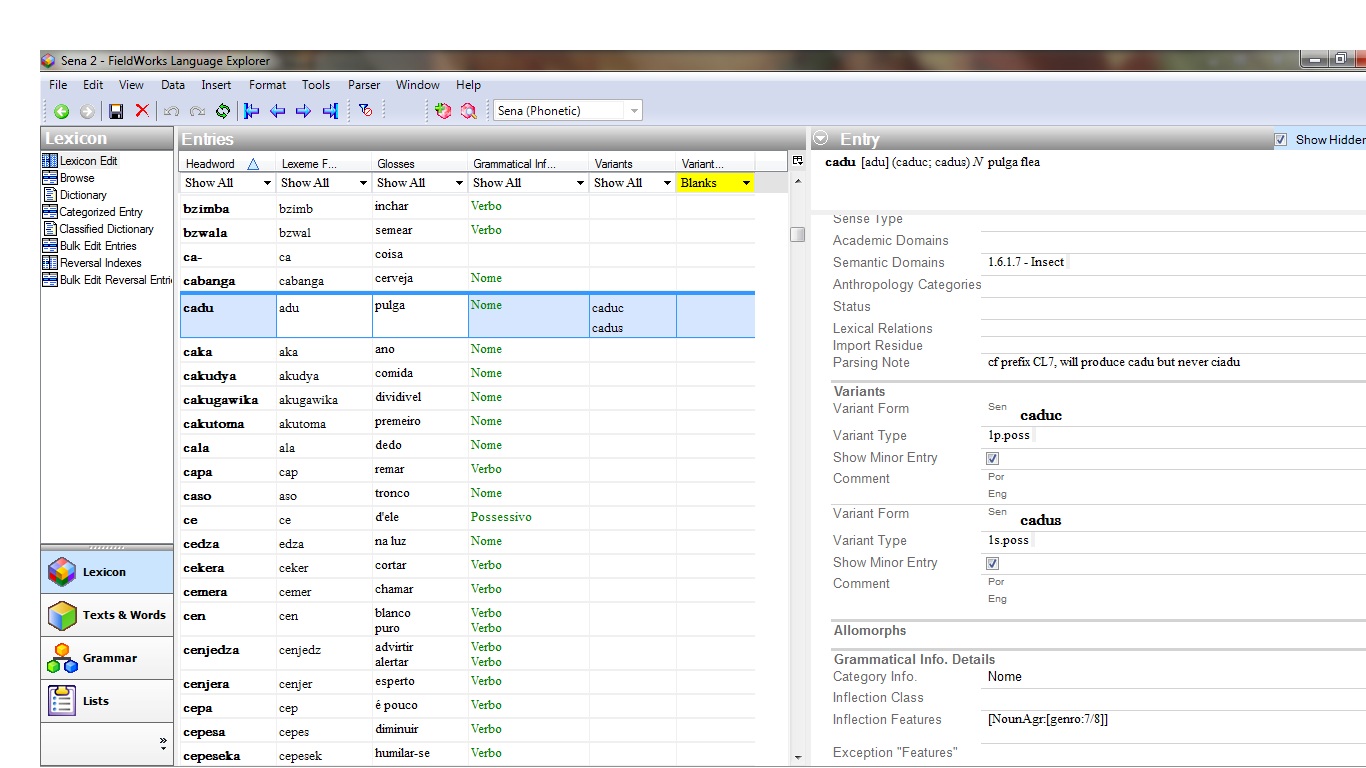
So far, method 3 seems the most favorable for the reasons mentioned above. However, the following features would make it much better:
- Be able to display each member of the paradigm together in something like a table that would aid analysis.

- Be able to add/edit members of a paradigm from that table rapidly (similar to the Categorized Entry tool to enter by semantic domain).
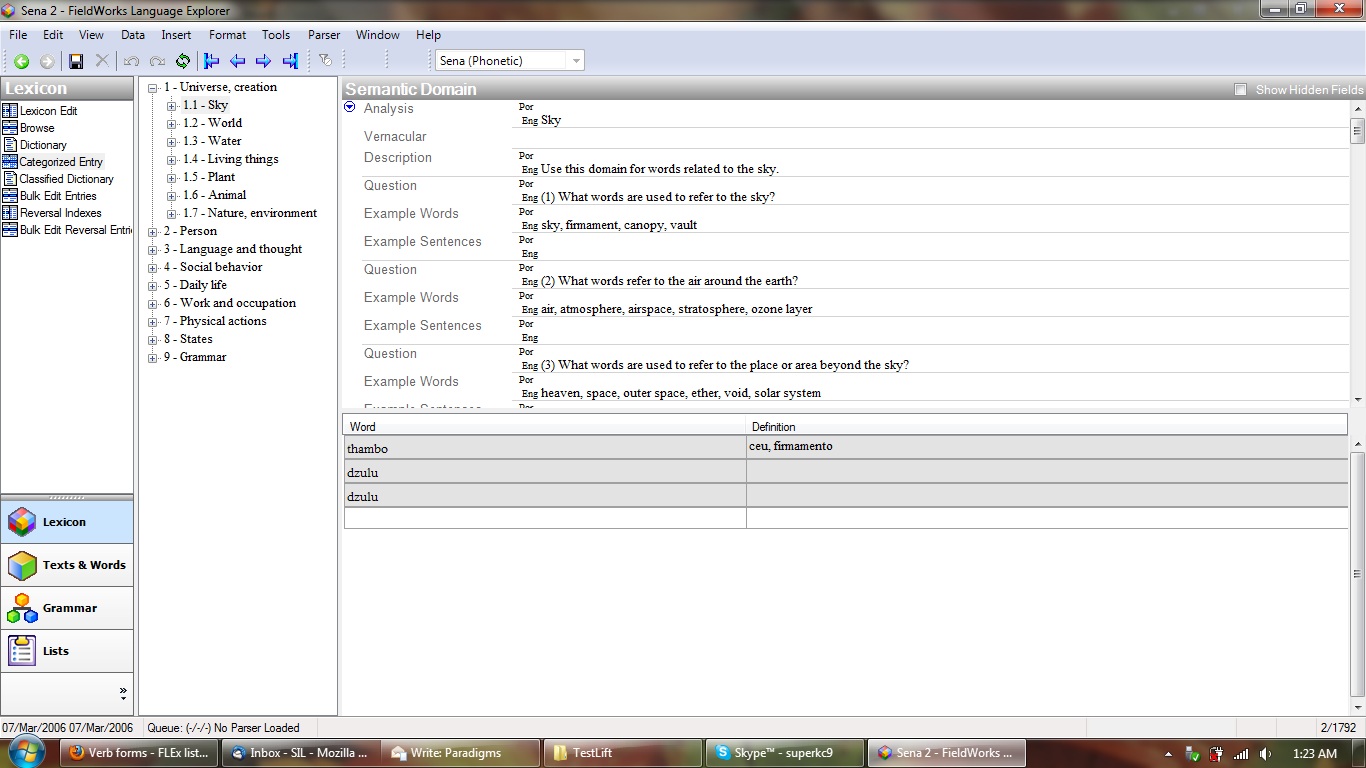
- Be able to export individual, multiple, or all words along with their paradigms (including null members) to other programs like XLing Paper for publication.
Of these proposed features, 1 and 3 are the most needed.
Kevin has spent the past couple days exploring the Fieldworks source code to find out how it works. He has come up with an idea of how to implement these features but has not figured out how to begin programming for Fieldworks. This is what he has come up with so far:
Add a new tool to the Lexicon area called Paradigm View (or something like that).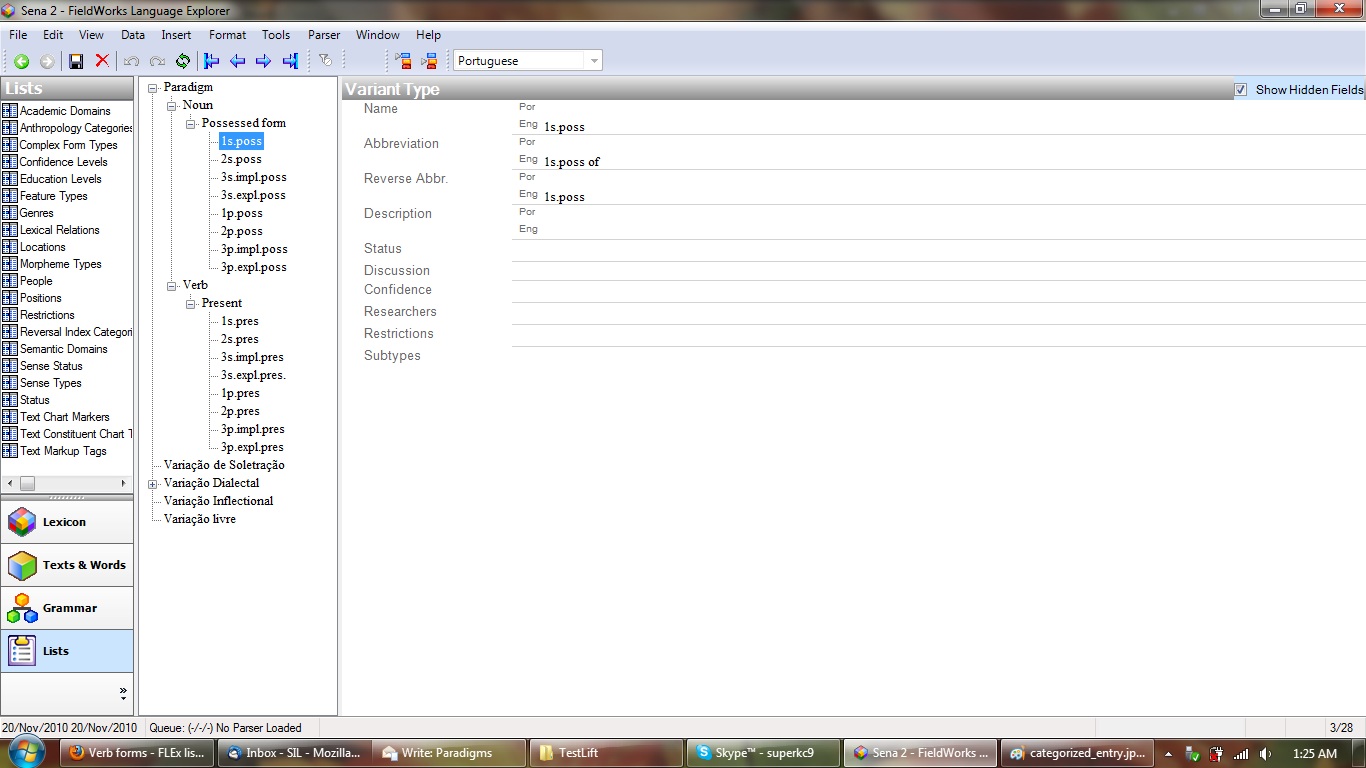
It would maintain the Entries pane of the Lexicon Edit tool to handle record navigation, but the right pane would be for displaying the associated paradigm(s) of a selected entry in table form. The members of each paradigm would be defined by sub-items in a Paradigm or Variant list. These tables would both display the members of the paradigm and allow them to be edited. They could be simple, with only a phonetic form in slots for each member with a link to edit existing variant entries to add more data later if needed. (A tone field may possibly be needed, but ideally the user could decide which form could go here.)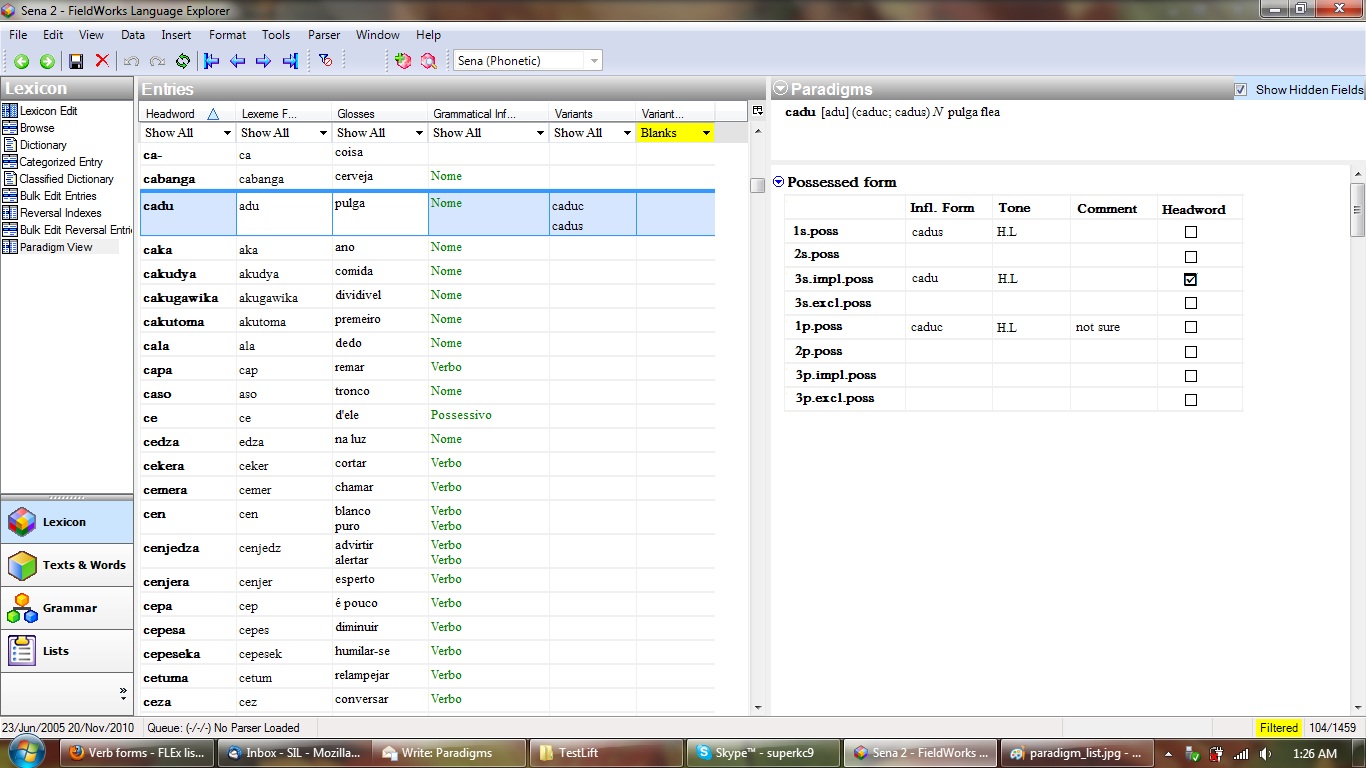 There would also be buttons or context menus that would allow new paradigms (defined in a List) to be added or removed to the entry or exported to XML or other programs. Included are mock-ups and screenshots of what something might look like along with an example paradigm defined by a List in XML format.
There would also be buttons or context menus that would allow new paradigms (defined in a List) to be added or removed to the entry or exported to XML or other programs. Included are mock-ups and screenshots of what something might look like along with an example paradigm defined by a List in XML format.
Hugh has had some additional thoughts on a paradigm tool:
Because of the comparisons we are doing in this project, and the comparisons that linguists are apt to do, sometimes it is helpful to be able to have the paradigm arranged differently at different times. For instance:
a)
| Variety 1 | 1st person | 2nd person | 3rd person | Plural |
|---|---|---|---|---|
| Word 1 | ||||
| Word 2 | ||||
| Word 3 |
b)
| Lexeme | 1st person | 2nd person | 3rd person | Plural |
|---|---|---|---|---|
| Variety 1 | ||||
| Variety 2 | ||||
| Variety 3 |
c)
| Lexeme | Variety 1 | Variety 2 | Variety 3 |
|---|---|---|---|
| 1st person | |||
| 2nd person | |||
| 3rd person | |||
| Plural |
Sometimes the grammatical part might be arranged across the top (as in examples a & b), and other times down the side (example c & the picture above under feature request # 1 repeated below as d).
d) Repeated from above under feature request # 1
An additional feature that would make the input very “user friendly” would be to be able to add a column to the table in the table view. If these paradigms were to be implemented as a list adding a column to a table, the user should be given the option to add this new column type to the paradigm list.
Also if I am adding a column or row to a table then I should be able to save that table structure (with out the data) as a table (or paradigm) template. Then I could quickly say that a word fits in X paradigm in Y language. I should then be able to quickly enter all the variants.
A language could have several types of paradigms in it. In addition to that a language might have several paradigms in it which relate to the same word type, ie. verbs or nouns or adjectives, etc. Lets take a look at a good Indo-European language like German and think of its verbs for instance:
- Regular verbs. Look at these on Cannoo.net
- Irregular verbs. Look at these on Cannoo.net
- Modal verbs. Look at these on Cannoo.net
- Sein, haben, werden. Look at these on Canoo.net
 |
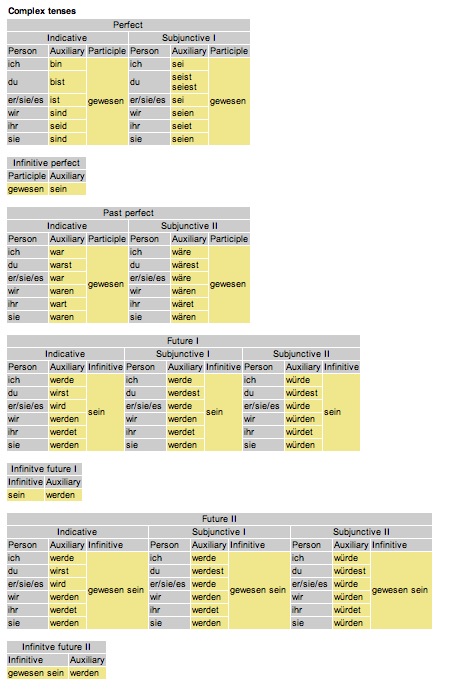 |
|---|---|
It would also be helpful if these paradigms could be individually exportable. In our case if we build a paradigm in one language of the 9 tightly related languages in which we are working, we would like to not have to rebuild the paradigms in the other 8 varieties / databases. Our current workflow in Meʼphaa utilizes 9 databases. We wish we could view all the data in one database, but with the use of variants if we were to have one variant for each variety and then also in each variety have all the variants of that word as they are inflected. We would have at least 81 variants per entry. This seems to be an overkill on the use of variant. We are currently not aware of how to export any one, and only one, list from FLEx, and then be able to import into another database.
XML of table view
<?xml version="1.0" encoding="UTF-8"?>
<lists>
<list>
<name ws="en">Variant Entry Types</name>
<abbr ws="en">VarEnt</abbr>
<item>
<name ws="en">Paradigm</name>
<abbr ws="en">Parad</abbr>
<item>
<name ws="en">Noun</name>
<abbr ws="en">inf. var. of</abbr>
<item>
<name ws="en">Possessed form</name>
<abbr ws="en">Possessed form of</abbr>
<item>
<name ws="en">1s.poss</name>
<abbr ws="en">1s.poss of</abbr>
</item>
<item>
<name ws="en">2s.poss</name>
<abbr ws="en">2s.poss of</abbr>
</item>
<item>
<name ws="en">3s.impl.poss</name>
<abbr ws="en">3s.impl.poss of</abbr>
</item>
<item>
<name ws="en">3s.expl.poss</name>
<abbr ws="en">3s.expl.poss of</abbr>
</item>
<item>
<name ws="en">1p.poss</name>
<abbr ws="en">1p.poss of</abbr>
</item>
<item>
<name ws="en">2p.poss</name>
<abbr ws="en">2p.poss of</abbr>
</item>
<item>
<name ws="en">3p.impl.poss</name>
<abbr ws="en">3p.impl.poss of</abbr>
</item>
<item>
<name ws="en">3p.expl.poss</name>
<abbr ws="en">3p.expl.poss of</abbr>
</item>
</item>
</item>
<item>
<name ws="en">Verb</name>
<abbr ws="en">inf. var. of</abbr>
<item>
<name ws="en">Present</name>
<abbr ws="en">present tense of</abbr>
<item>
<name ws="en">1s.pres</name>
<abbr ws="en">1s.pres of</abbr>
</item>
<item>
<name ws="en">2s.pres</name>
<abbr ws="en">2s.pres of</abbr>
</item>
<item>
<name ws="en">3s.impl.pres</name>
<abbr ws="en">3s.impl.pres of</abbr>
</item>
<item>
<name ws="en">3s.expl.pres.</name>
<abbr ws="en">3s.expl.pres of</abbr>
</item>
<item>
<name ws="en">1p.pres</name>
<abbr ws="en">1p.pres of</abbr>
</item>
<item>
<name ws="en">2p.pres</name>
<abbr ws="en">2p.pres of</abbr>
</item>
<item>
<name ws="en">3p.impl.pres</name>
<abbr ws="en">3p.impl.pres of</abbr>
</item>
<item>
<name ws="en">3p.expl.pres</name>
<abbr ws="en">3p.expl.pres of</abbr>
</item>
</item>
</item>
</item>
</list>
</lists>
Response and related requests
Our request is related to request LT-12743 "Add a custom field that is a table (e.g., for paradigms)" This is different than what we asked. This other issue request has a single data storage back-end while ours has multiple data containers in the back end. The UX may be similar, and be trying to meet the same felt need, but we go through a lot more detail to show what could be done in the FLEx UI and we feel our suggestion will integrate with the parser easier.
Beth Bryson added a comment - 18/Jul/14 2:31 PM
I don't know if we can do anything about paradigms at this time, but we need to at least look at it as we are deciding what to do as part of the Import Improvements project.
Request from the Meʼphaa Language Documentation team for word relationship tracking in FLExAuthors
- Kevin Cline
- Hugh Paterson III
- Becky Paterson
- Steve Marlett
Date submitted to FLEx Dev Team
- 2 December 2010
Context
We are working from Mexico with (estimating) 9 varieties of Meʼphaa. These would include the languages which fall under the following ISO 639-3 codes: [tcf],[tpl],[tpx],[tpc]. We have a team of 4 trained SIL linguists. We are eliciting words in paradigms and comparing these paradigms across the varieties we are investigating.
Request
It has also come to our attention that there doesnʼt seem to be a clear way to mark the reflex of a given word. The challenge in marking the relationships is primarily two fold:
- How does one establish the difference in headwords with the same meaning in two currently spoken varieties?
- How does one establish a headword in the proto-language?
We have seen the etymology field but this seems to slightly miss the relationships we are desiring to track.
Consider the diagram and the examples below:
We want to be able to track the relationships between {A} and {B}; {A} and {C}; and {B} and {C}.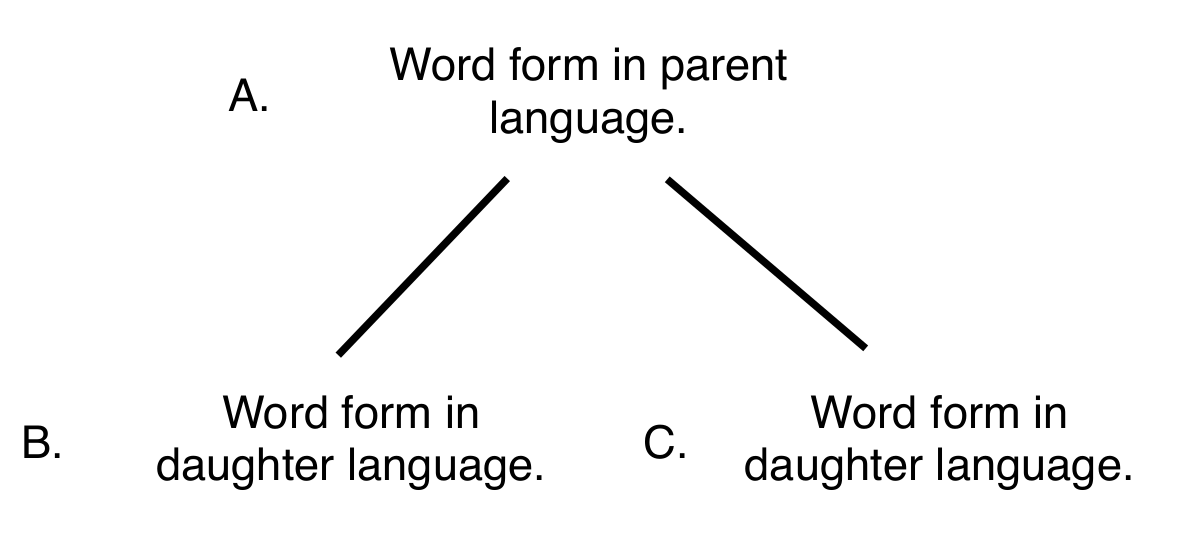 To restate the above; how do we distinguish between {B} and {C}? And how do we distinguish between the sets of {A} and {B, C}.
To restate the above; how do we distinguish between {B} and {C}? And how do we distinguish between the sets of {A} and {B, C}.
Variants {B} and {C} are known as reflexes of {A}.
Variant {B} is known as the cognate of {C}.
The relationships between [“A” and “B”] and [“A” and “C”] are related to their phonological shape rather than their semantic meaning or their situational use. Although it is also important to link the terms which have been replaced, back to the terms which have replaced the terms. (i.e. in order to note the direction of semantic and lexical shift.)
The purpose here is not to do or provide a tool for historical-comparative linguistics, but rather to appropriately and accurately model the relationship of words to each other. This makes a lot of sense when dealing with multiple varieties like we are.
Summary
Sometimes a custom relationship is necessary between two elements of an entry (not of the same entry), it is not very clear how to add these custom relationships.
General Me'phaa projet Network set-up
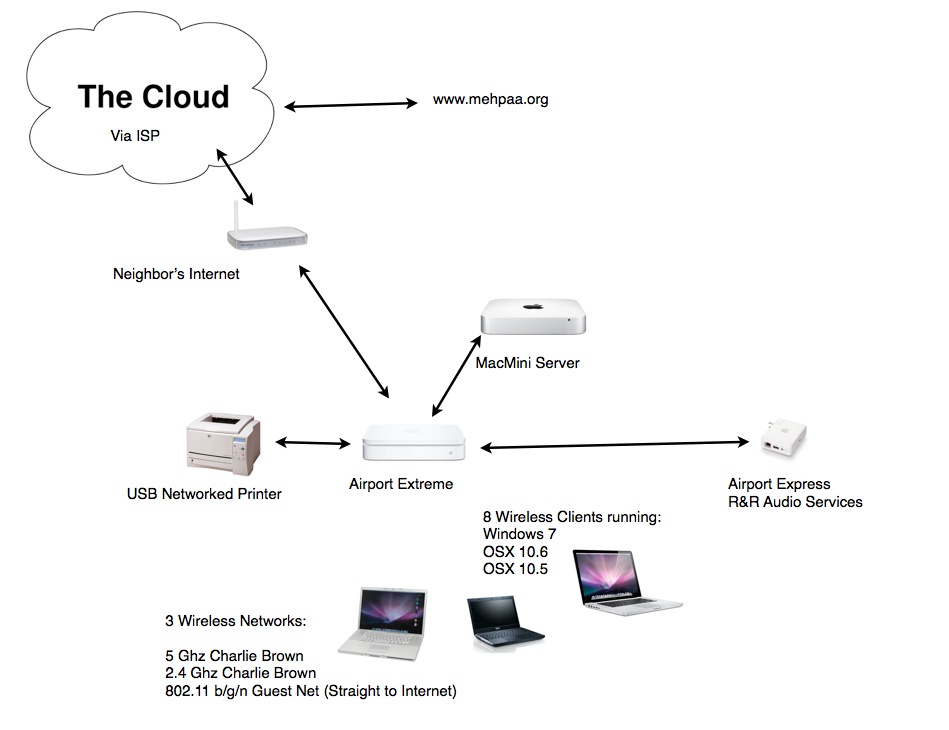
The diagram above roughly illustrates our network setup. This set-up might be typologically rare in terms of language documentation field stations for several reasons. But we had reasonable power (both in quality and quantity), though there were some power outages. And we had high-speed internet.
In terms of network set up there was the need for a direct internet direct connection for each of our staff's computers, so that we could have a team network with people off site. This was acomplished through a single network on one subnet, and then a separate network (subnet) for guests or language consultants, who would bring their own computers to have a “drop box with us”. To fill this need we could open our network to each of the consultants or we could use an outside service like Dropbox. – I am not sure why we did not use DropBox. Eventually we used Google spreadsheets for collection word frames (because FLEx does not support this). Our consultants might have been atypical in that they also had their own computers and had some familiarity with computer use.
Server and data store Backup
Best practice for backup calls for a three way backup plan.
- An onsite backup.
- An “across town” backup. Where a (at least weekly) backup is held by a friend or colleague across town.
- And an out of country back-up.
This three way backup is to:
- Protect from mistakes or equipment failure.
- Protect from theft.
- Protect from catastrophic events.
Our onsite backup was handled by Time Machine.
We would switch out our Backup drive every week and give it to a colleague across town.
We attempted to use KKoncepts for our offsite backup. (KKoncepts did not work out because it was based on a simple rsync script and every time we tried to re-organize folders in our corpus it would try and re-sync all of the Gigabytes of data which lived under the folders.) The DropBox service is much more efficient and looks at the block level (inside the file) and only updates things that have changed. It then looks at the tree structure and mirrors what is currently on the clients computer, rather than re-uploading the content.
1. The reader here should realize that there are literally thousands of bug reports and feature requests on file at the FLEx bug tracking instace. There are only about four programmers who work on FLEx. So, the back log can happen quickly, and forward progress is very slow. ↩
2. For further commentary on the Jira issued please see the building an online community section. ↩