FLEx Ecosystem Data
Get Blog Post from insite Wiki.
http://hugh.thejourneyler.org/2012/the-data-management-space-for-linguists/
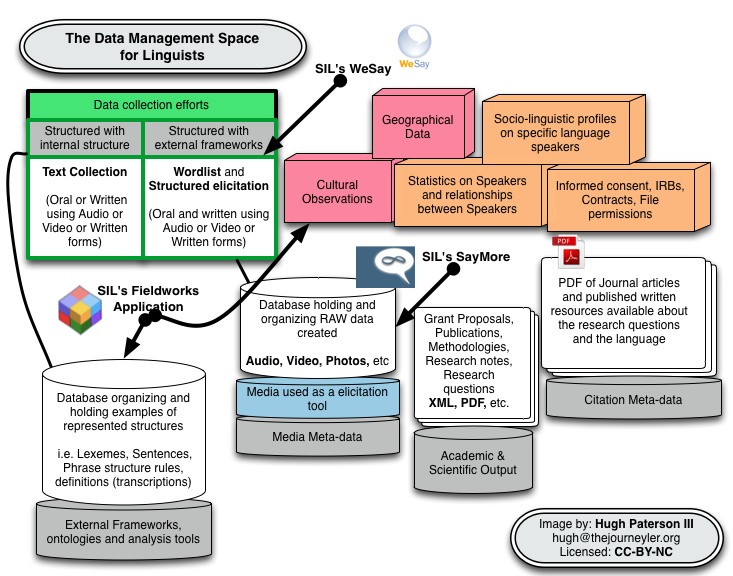
- Created by Paterson, Hugh, last modified on [Apr 26, 2014](https://wiki.insitehome.org/pages/diffpagesbyversion.action?pageId=132023757&selectedPageVersions=33&selectedPageVersions=34)
Some filtering Required
Reading this may require some filtering. This is my second exposure to a LSDev Project Proposal. The first one was for phonology assistant and resulted and a lot of email traffic on the LDL, and a blog post here: The Hidden Cost of Not Working Together.
Scratch Pad
Please note that part of this is unfinished commentary, and some of it is just some RAW notes taken from some email conversation over the last 18 months (starting in Feb 2013). I have put them here as a place holder while I read through the existing proposal and think through my reply.
The full document and Vocabulary Manager 6.0 proposals is available here: https://docs.google.com/a/sil.org/document/d/1UZR0Kx1YihBhL3p19QTpTlpK_Asp4Yu8r_niiuwfRbo/edit#
Be aware that the referenced document may change over the course of time as it a live working document.
Synopisis
I am encouraged that the LACL team and LSDev are communicating about this resource. I think that there is a real need for this resource. However, I feel the LACL team has failed to adequately do several things:
- establish the business need and connect the tool to SIL corporate strategies
- adequately defined the problem space that this software is trying present solutions for
- work with other SIL Domains like the Literacy and Education and the Lexicography service group, therefore key value propositions for end users of this tool are not explored as deeply as they should be
- the existing options on the market (both open source and commercial) are not explored sufficiently
- the LACL team has not brought to SIL's consumer data management processes the needs for this data. (not to say that SIL has any mechanism for them to bring this to - which seems to be a GLPS level problem). That is, data for this resource should be interacting with FLEx Bridge, LanguageForge, and Webonary hosted Data solutions. However, there is no current coordination of these data from a consumer interest point of view.
Finally the framework which LSDev provides for LACL to communicate with them through, I believe, has some significant drawbacks due to managerial processes and practice. One of the affected drawbacks is a lack of focus on user centered design for solutions in the problem space encountered by users, focusing rather on "product development".
Comments about the executive summary
So, to start quoting with my comments inter spliced below.
Vocabulary Manager 6.0 is a software that enables rapid vocabulary acquisition through association of sound to image for language learners who need to learn a language efficiently.
To the LACL folks part of ILPT. Which service does this software development fall under? In ILPT and GLPS we are talking about services. The commissioning of this software should fit under or as part of the goals of fulfilling one of the departments' services and be under one of the ongoing programs. I do not see any mention of these services in this proposal. I feel this absence significantly weakens this proposal.
The first thing is just to put it back on our website so people can easily download it and use it. It now has advocates, and it would probably be helpful to get the source from Bob Eaton so LsDev can take responsibility for any maintenance needed.
This paragraph raises several questions in my mind. First, the comment about the website, directly speaks to an issue of communication strategy about the software. If the software is situated within the context of a service then this will get sorted out with the necessary details about how to put it on the website, and why and for whom and under what license, and how product support will be handled. But, the approach here, and the context I am understanding the situation to be understood as is that the LACL department thinks that LSDev owns the product, and LSDev says they need LACL to fill in the requirements. My recommendation is that everyone come to realize that LACL needs to be the product owner and contract out the development to LSDev. By just putting a downloadable item on a website does not actually solve this problem space - in fact just having a vision for a product does not actually define the problem space that we are trying to find a solution for. One classic example of ownership being a fundament part of this process is the issue of product support and how that will be handled. SIL has this issue with every product it produces - and product support (in terms of web based access to support materials and self service solutions) is minimal. The SIL model of project support requires personal interactions. Rendering tier 1 user level product support should be the responsibility of LACL not LSDev!
As the ILPT User Experience Analyst, my concern with this product is: "what is the total experience we are delivering to the end user?"
The second comment of concern in this paragraph is the one about access to the source code. Vocabulary Manager has been advertised as an SIL product in the past and had a place on the old SIL.org website. It would follow then that the code should be copyright SIL International. If SIL International does not have access via a central repository (private or public like github) with its code in it then we have a serious ownership and asset stewardship issue. It should be clear that the owner (as I proposed above should be LACL) and the contractor (as I proposed above should be LSDev) should have access to this code.
The last thing I am going to say about this paragraph in the executive summary is that it is emotionally written, rather than logically written. That is, we (SIL) should not be adding something to the website and then fixing the product. We should be fixing the product and then making it available.
The second thing would be to tweak the Windows version to make a few windows smaller, so that it is usable on netbooks and other Windows machines with smaller screens.
I think we can summarize that this paragraph is saying that the program (Vocabulary Manager) as it is currently is built assumes that users behave in a manner which is simply not true anymore. That is, the context surrounding the communication event (including the execution of code) has changed. This paragraph is also the first clue that what is really happening here in this proposal is that the champions are saying that the current product does not fit the problem space for which the product was designed. - That there are new design requirements. However, nowhere in the project proposal are past design requirements listed or are future design requirements explicitly stated. This sounds to me as a two fold problem: (1) unnecessary exceptions on the part of LACL upon LSDev to be able to understand the tasks for which the tool was designed - an interdepartmental communicative problem, and (2) that the LACL team has not explicitly defined the problem space and the user interaction that they need - an inherent planning problem.
The third thing would be to internationalize it and localize it into various languages.
i18n should be 'permission to play' (or also this link: http://www.coherent-coaching.com/cores-vs-permission-to-play-values/) feature that LSDev tries to force on each of their clients to require in their design specs on products out of the gate. SIL International is a multi-lingual corporation in its operations divisions, let alone by any measure of its consumer market. By LSDev not setting the exceptions to its clients on what to expect from an LSDev project this waists the time, communicative energy and expectations of the champions. If Internationalization is truly 'permission to play' issue at the GLPS software level then this should affect which software we advertise from SIL.org and how SIL the corporation leverages its presence in the software markets/products which look to target the language development engagement space. One practical application for LSDev of this would be to be to host a GlotPress install and facilitate the localization all of SIL's software products as I mentioned in this comment to LSDev: Re: Discussion of commercial localization tools.
There is also some interest in having it run on tablets and phones, but we don’t yet have adequate user requests to know which platforms would be most valuable (e.g., ios or android, tablet or phone).
The above paragraph is interesting and concerning in serval ways. First, it talks about metrics, saying "we don't have adequate user requests", however, there are two issues with this: (1) there is no explicit metric of how many requests are actually sufficient to warrant work, or (2) there is no explicit way to collect user feedback .i.e no forum or user-voice panel. So even if there were a quantitative level of interactions from users or potential users, there is no structured tracking of qualitative data about improvements or use cases in which users are deploying the software. In essence as things currently exist this requirement for more input will never be reached. Another related issue this paragraph rests upon is SIL's corporate strategy for first (or alternatively primary) engagement. Is that the mobile device or not? So, this proposal needs to have ties back to the corporate engagement strategy and to the business case for this software. I would like to add here that based on my prior conversations with Jackson, Ellen and [Bennett, Fraser](https://wiki.insitehome.org/display/%7EFRASER_BENNETT\) that my understanding is that there is interest on the part of the LACL team in pursuing content engagement strategy where the Mobile device is the primary engagement tool. (Ask [Bennett, Fraser](https://wiki.insitehome.org/display/%7EFRASER_BENNETT\) for materials provided to him on Content development by Hugh Paterson - it’s a PDF.)
(Import from FLEx has also been suggested, but there is already a good tool for making flash cards from FLEx.)
Here is where I think the most fundamental change assumed in the proposal is understated. SIL does not have a unified consumer data use strategy. Every product team wants lots of people to use their product (presumably - communication patterns around these products may indicate otherwise). As product users/consumers use our products there should be a seem-less integration of enduser benefits as they move through the various problem spaces for which SIL has created solutions. It is my opinion that SIL need to work to consolidate the enduser experience across these software experiences. This end user engagement strategy needs to be the bases of our software development activities and our partnership endeavors. If something does not fit into the strategy then it needs to be sacked; if however, the strategy needs to be reformulated then this can also happen but can not happen on an isolated scale and must be addressed as a matrix.
For instance when should users use FLEx, and why would it be useful to them to use it? This proposal in several places argues that VM6.0 will encourage earlier usage of FLEx. I am not against this by any means, but I want to be clear and ask: Is the real metric and benefit (to whom) more FLEx users? Or does the real metric need to be a count of active SIL Language Data Service users? It is already acknowledged by two SIL Staff with development skills that FLEx data is helpful in language learning, however, neither one has approached the question of heritage language learners, though both could certainly be used in such a case. Such an approach would tie VM in with literacy programs and products like Bloom. Another un-attested connection is the connection between VM (and whatever it will become) and Webonary or online forms of lexical and text based materials. The the User Experience and User Interface connection between online dictionaries and language learning software is highlighted in the video introducing learning with texts.
Language Learning Software which have an interface with FLEx Data
- VocabLift a HTML5 + JavaScript app which works in the browser https://github.com/somelinguist/VocabLift v0.3.2 by Cline, Kevin L. most recently Updated 2014-02-??.
- One Way "sync" from FLEx XML to ANKI https://ankiweb.net/shared/info/915685712 v0.8.x, by Unknown User (jonathan_coombs) most recently Updated 2014-04-04.
- Talking Language Helper: http://www.canil.ca/joomla/index.php/resources/talking-language-helper FileMaker Pro runtime version instance created from LIFT data by Hayashi, Larry
I think that the best way forward is to ask the question: What is the big picture beyond just the VM6.0 program? and then decide on which path will lead us down to those kinds of results. The following diagram illustrates what I believe are some of the issues in the problem space being approached but have not been fully articulated.
Following a clear display of the problem space and of the competing commercial and open-source solutions, there are several options available. But if cloud integration or multi-service integration is part of the larger picture, and SIL is committed to development of its own platform, then I would suggest a deeper look at VocabLift because it is a browser based HTML5 app. HTML5 apps can be bundled for Android and iOS. This would potentially give SIL the opportunity to develop once and deploy in multiple deploy. SIL is already engaging in HTML5 app development with RAMP. There has been discussion about deploying RAMP in a similar set of contexts. This option stands in contrast to having a C# development for Windows, a Mono translation for Linux and then a Java based app for Android, and no Solution for OS X or iOS. But paramount to any decision about computing OS or programing language based decision, the problem space needs to be defined. And then the platforms question needs to be answered. Then we can talk about programing languages. If sync service are at all part of the picture then an API becomes important, and that adds another level to the technical discussion. (But current managers should not be afraid of the depth or cost of technology, if this is the direction that SIL needs to go to maintain its desired impact in language development.)
Reminds me of the discussion here
http://www.kaushik.net/avinash/multi-channel-attribution-definitions-models/
Presentation on VocabFLEx by Scott Dysart
Other Language Learning flashcard like applications
http://www.memrise.com/course/209740/basic-kaby/
http://lingoversity.software.informer.com/
http://wordquiz.software.informer.com/
http://pauker.sourceforge.net/
http://adornthetruth.com/nikamo/
http://www.fluentin3months.com/learning-with-texts/
https://play.google.com/store/apps/details?id=com.ichi2.anki
http://ostatic.com/blog/five-open-source-flash-card-apps-to-make-rote-learning-easier
Cross-platform
There is a data exchange format for card decks.
https://itunes.apple.com/us/app/flashcards-deluxe/id307840670?mt=8
Are we going to sell text books?
http://www.textfugu.com/pricing/
Language Informant
http://sourceforge.net/projects/langinform/
Key Features for immediate needs:
- Put program back on web site.
The proposal suggests that the software needs to be put on "the website". However, "the website" is never defined. SIL engagement strategy needs to inform service managers on what the requirements are for listing software on SIL.org. What are the standards for software we recommend and link to? External Communications (or just Communications) does not have a strategy, but this does not mean that there shouldn't be a strategy. Just because we have a product does not mean that in any stage of development that it goes on sil.org (or more explicitly, its stage in development should determine how it is available throughout SIL.org). The impact of the addition of LACL software to sil.org needs to be coordinated with various SIL domains, SIL International Communications and the various programs administered at the GLPS level of SIL International.
Key Features for tablet version:
Import a data set from the Windows version. (Creating one on a tablet is probably too hard to design.)
Association tool: select a data set, cycle sequentially or randomly through items, showing the picture (and/or text) and playing the sound. Repeat/Next.
Comprehension tool: display all pictures in data set, play random sound, user tries to select correct picture, inform right or wrong.
Optional: spelling tool: play sound, user attempts to type it.
Optional: Collect data: each item has a name, a sound file, possibly a second sound file giving the word in context, a picture, and optionally a vernacular text. (Picture can be omitted.) The current version proposes paths for these files, but a tablet version would probably need some other way...possibly bring up a picture chooser and similar approaches. Maybe data sets get created using the Windows version and imported?
How our Data model needs to treat IP Issues
IP issues: Onion Model: Re: Task force - publishing online dictionaries
Improving Our Intellectual Property Policy and Practice comment about data.
The challenge of the FLEx data-structure and the ignoring of contributor metadata, including rights at the 'entry'/'field' level.
About partnering
Some questions about the positioning of partners in the industry. In this proposal there is the suggestion that SIL might look to BibleMesh to become a partner. I would like to know more about the BibleMesh Platform:
- Is BibleMesh and Cerego owned by the same people or is BibleMesh contracting out to Cerego and making their business off of the Cerego engine? - Who, SIL Partners with and where they fit in the ecosystem is really important for SIL's future sustainability in the language development services industry. – This question is partially answered in the quote below.
- If BibleMesh ends its service operations (or is boughtout), and therefore can not continue offering SIL access to the Cerego platform then where does SIL's consumers go? Does the SIL Brand take a reputation hit for this? or are we merely connecting our service consumers into another network and supporting that other network?
- What happens to the content that SIL's consumers/Biblemesh users have spent hours creating, is it transferable to another platform or is it locked-in with this vendor (who is the vendor is it Cerego, or is it BibleMesh)?
- Is the content created archivable in SIL's Language and Culture Archive? If so, how? Is materials in the language and culture archive accessible to content creators in app? If so, how? Who owns the produced content? Especially if an SIL staff creates the flash deck as part of their job assignment?
- If Cerego http://cerego.com/how_it_works is the real engine behind the power of BibleMesh, then why would SIL try and partner with BibleMesh rather than Cerego? – This question is partially answered in the quote below.
- Is BibleMesh offering to integrate our languages into their application under their marketing or are they offering us the opportunity to completely market this under our own brand? independent of their name?
- On concern I have is that SIL has had contracts with other organizations in the past to use their language learning software, but SIL has never followed up or taken advantage of these opportunities. This is in part because these contracts/MOUs have never become part of our corporate consumer engagement strategy. If we do go with creating an app or using BibleMesh, then I think we need push this hard. Within the first two months we need 10 examples - people can import from FLEx and we have that many FLEx projects going via Webonary already. We need to advertise this software at the Hawai'i Language Documentation conference (happening in March 2015!!) in both the technology session and in a paper. The conference is accepting abstracts now for language learning materials made from language documentation materials.
- Is this agreement with BibleMesh Exclusive? That is can they make the same agreement with someone else? or other language development organizations? If they can, then that might affect the perceived value of and SIL product via partnership.
- Because the greater portion of the VM6.0 proposal (which seems to be stemming the interest in BibleMesh) is coming from LA CL and not a combination of user-facing service managers (like literacy and lexicography) there seems to be an unbalanced focus on training SIL staff and SIL partner staff, rather than on language learning also conducted by minority speakers which is on of the core elements of language development. Therefore, if this software solution (especially on a BibleMesh platform) is successful then, does it become a solution which does not scale to all the language development project that SIL is involved in (as these SIL trained staff will want to use the same tools they are familiar with to provide solutions for their customers/who-they-serve)? This applies on both the socio-political spectrum (objections to using "bible software" in hostile environments) and the in the software licensing spectrum (potentially millions of users rather than thousands of users). SIL needs to be upfront with both BibleMesh and with software end users.
- Who has god level access (total administrative power) to the user (profile and interaction) data and to the content? Is this company then a US based company? - The implication here is that there is a lot of data about individuals and if this is a US company then US laws apply regardless of where in the world the servers are located. If servers are located elsewhere then other countries' laws may also apply. #Snowden
Here are two pieces of Nick’s earlier correspondence that may be helpful….or might raise more questions!
Note: iKnow is the vocab learning program in the Biblemesh courses.
Essentially, iKnow is the Japanese branding mechanism for the larger company Cerego. I will generally talk about Cerego, though at times the iKnow name gets used when discussing learning products originating from the Japanese market (for example, the mobile application is still branded iKnow). Perhaps XBox's relationship to Microsoft is a good analogy, though such would be grossly disproportionate!
The foundation that owns BibleMesh acquired a significant share in Cerego for use on our biblical language projects. We work closely with the Cerego development staff to develop our learning apps and to enhance their core offerings. As you have seen, we use Cerego tech constantly in our reading courses for vocabulary training. As we make advances in Cerego tech, that gets implemented back into the reading courses.
As we discussed at the BT conference, I am in complete agreement with Ellen that we want to move well beyond either analytics, linguistic documentation, or simple gloss-based learning when it comes to language learning. While I'm still wrestling with how to incorporate TPR-style learning into the online environment (perhaps through tapping into a Wii-like gaming system), these multi-function internalization and production goals form the core of what BibleMesh/Cerego is trying to develop. I would add that social feedback, cohort-drive accountability, and global access to learning data are also core values.
Vocabulary Manager doesn't run on modern OS's and there is a proposal to update it. However, we also have a generous offer from BibleMesh to extend their Greek and Hebrew learning software to teach any of the languages we work in.
To figure out if this is a better way to go, we need to set up a comparison between the two tools. I need a functional Vocab Manager database that has pictures, sound, etc. Then we will try to get that same information ported over to the BibleMesh software (which also runs on mobile platforms) so that we can do a side by side comparison.
But... I don't have any Vocab Manager data.
It is interesting that this should come up. One of my SIL colleagues has assumed that the "Vocabulary Manager" project is dead. Therefore he has taken the task of creating an app which works across OS platforms, works from the LIFT files you create in other apps and creates a flash-card like set of interactions (including media) which can be used to help one learn language. You can download the open source app here on github: https://github.com/somelinguist/VocabLift
FYI: the github release runs a bit behind the sourceforge release: [http://sourceforge.net/projects/vocablift/files/Releases/]\(http://sourceforge.net/projects/vocablift/files/Releases/)
In support of my claim that the whole idea behind "vocabulary manager" should be re-factored with modern language learning tools and theories in mind, I am reminded of a Proposal on Insite that I wrote a few weeks ago:
https://www.wiki.insitehome.org/pages/viewpage.action?pageId=129696611
I think in some ways if we move from the idea of app based data to services based data then a cloud solution becomes the logical conclusion. Vocabulary Manager has at its core the idea that expats need to learn languages. However, there is a lot of need for heritage speakers to learn the same languages.
From dave roberts via the LDL
Hi everyone,
this isn't really a linguistics question, but I think it may be of interest to group members
I've just spent an evening adding 20 Kabiye lessons to Memrise, a crowdsourcing language learning tool.
http://www.memrise.com/course/209740/basic-kaby/
I recommend this as a simple and effective way to increase the visibility of minority languages on the web.
Dave,
Memrise looks really cool. Nice clean interface. Does it support audio? I think that would be of some importance here to make the lessons more functional for real learning - BTW my wife has been using a free iphone app for language learning, so I think there is real future here in being able to create resources like this. Also where is the source of the data indicted? How does the casual discoverer of this data know that this data is (1) real and (2) accurate?
Did you know of the Vocab Lift project? one SIL guy from Mexico is has created a computer based app which will allow the user to take their FLEx LIFT file and create language learning lessons from it. (viewable on the user's personal computer). https://github.com/somelinguist/VocabLift
I think there is an additional question which should be asked too: Is the data yours to share (and create lesson on the open web)? (*not just you personally Dave, but many of us in language work.)
For SIL staff the data collected belongs to SIL, by virtue of work for hire (unless MOU's indicate otherwise).
For those with insite access SIL did just release a update (13 dec 2013) to the Application Statement for the Intellectual Property Policy.
- Hugh Paterson III
9 Comments
Thank you for mentioning VocabLift Hugh. I've started entering the words I've learned...or rather been exposed to..in FLex for the purpose of reminding myself how to use FLex. Now I can get a second benefit from that work for language learning.
Reply [Edit](https://wiki.insitehome.org/pages/editcomment.action?commentId=132023777&pageId=132023757\) [Delete](https://wiki.insitehome.org/pages/removecomment.action?commentId=132023777&pageId=132023757&atl_token=1bad93b270cf3693559d410e6c323ef84f403a55\) [Like](https://wiki.insitehome.org/pages/viewpage.action?spaceKey=%7EHUGH_PATERSON&postingDay=2014%2F4%2F17&title=Some+thoughts+about+the+Language+Software+Project+Proposal%3A+Vocabulary+Manager+6.0\) [Apr 17, 2014](https://wiki.insitehome.org/display/%7EHUGH_PATERSON/2014/04/17/Some+thoughts+about+the+Language+Software+Project+Proposal%3A+Vocabulary+Manager+6.0?focusedCommentId=132023777#comment-132023777)
Paterson, Hugh AUTHOR
Scott, I haven't even started with the post yet. This is just my chicken scratch of a note pad... You should read it again in a few days and comment on what I have to say then (also)... in the mean time check out VocabLift and see if it works for you, maybe you can send me some screen shots.
Reply [Edit](https://wiki.insitehome.org/pages/editcomment.action?commentId=132023779&pageId=132023757\) [Delete](https://wiki.insitehome.org/pages/removecomment.action?commentId=132023779&pageId=132023757&atl_token=1bad93b270cf3693559d410e6c323ef84f403a55\) [Like](https://wiki.insitehome.org/pages/viewpage.action?spaceKey=%7EHUGH_PATERSON&postingDay=2014%2F4%2F17&title=Some+thoughts+about+the+Language+Software+Project+Proposal%3A+Vocabulary+Manager+6.0\) [Apr 26, 2014](https://wiki.insitehome.org/display/%7EHUGH_PATERSON/2014/04/17/Some+thoughts+about+the+Language+Software+Project+Proposal%3A+Vocabulary+Manager+6.0?focusedCommentId=132023779#comment-132023779)
Hugh, you wrote:
...the framework which LSDev provides for LACL to communicate with them through, I believe, has some significant drawbacks due to managerial processes and practice. One of the affected drawbacks is a lack of focus on user centered design for solutions in the problem space encountered by users, focusing rather on "product development".
The vision statement for a software development proposal is supposed to be the following:
"Craft a statement based on the product vision, and some of the problems or unrealized opportunities users are encountering. The vision for the project would be to address these problems and opportunities and thus help users be more productive."
So, I think the proposal process is on target. However, there can be some improvements to the process and I will recommend to Rob Scebold that more of a emphasis is placed on defining the user community in the proposal. Currently, the form asks: "Who will use it?" and you can get away with a few words in response. I'll propose that this question is made more prominent, but also requiring the proposal to present more evidence from the user community that this product will fill a need. This is one thing that would have helped the Vocab Manager proposal.
- Reply [Edit](https://wiki.insitehome.org/pages/editcomment.action?commentId=132025385&pageId=132023757\) [Delete](https://wiki.insitehome.org/pages/removecomment.action?commentId=132025385&pageId=132023757&atl_token=1bad93b270cf3693559d410e6c323ef84f403a55\) [Like](https://wiki.insitehome.org/pages/viewpage.action?spaceKey=%7EHUGH_PATERSON&postingDay=2014%2F4%2F17&title=Some+thoughts+about+the+Language+Software+Project+Proposal%3A+Vocabulary+Manager+6.0\) [Apr 24, 2014](https://wiki.insitehome.org/display/%7EHUGH_PATERSON/2014/04/17/Some+thoughts+about+the+Language+Software+Project+Proposal%3A+Vocabulary+Manager+6.0?focusedCommentId=132025385#comment-132025385)
- AUTHOR
Higby, Doug, I agree, that a more specified user class(es)/persona description would have helped the VM 6.0 Proposal. However, in my comment about the user context v.s product development I am taken back to when [Starwalt, Coleen](https://wiki.insitehome.org/display/%7ECOLEEN_STARWALT), First approached the LDL about Phonology Assistant. As champion, her first approach was to ask for input from PA users, not to investigate and define the problem space, or how the competition is affecting the LSDev product or impact on the problem space and therefore the class of potential users. (Please note: I am not faulting Colleen here on this, I think the LSDev form and the title "product Champion" sets up any champion to go out there and talk up the LSDev project, rather than focusing on the problem space and delivering a tactical advantage to SIL operations through finding a solution.) So my synopsis statement is not just based on this one interaction with a LSDev proposal or a single champion. For my interactions about PA see: The Hidden Cost of Not Working Together; which the cost of not working together rings truer and louder, and seems to be a theme here as evidenced by the 3 separate projects which are not working together on a single solution for a flashcard based solution for using FLEx data in language learning. Give us another 3 weeks of discussion and I would not be surprised if there isn't a 4th project somewhere in Africa.
- Reply [Edit](https://wiki.insitehome.org/pages/editcomment.action?commentId=132025386&pageId=132023757\) [Delete](https://wiki.insitehome.org/pages/removecomment.action?commentId=132025386&pageId=132023757&atl_token=1bad93b270cf3693559d410e6c323ef84f403a55\) [Like](https://wiki.insitehome.org/pages/viewpage.action?spaceKey=%7EHUGH_PATERSON&postingDay=2014%2F4%2F17&title=Some+thoughts+about+the+Language+Software+Project+Proposal%3A+Vocabulary+Manager+6.0\) [Apr 24, 2014](https://wiki.insitehome.org/display/%7EHUGH_PATERSON/2014/04/17/Some+thoughts+about+the+Language+Software+Project+Proposal%3A+Vocabulary+Manager+6.0?focusedCommentId=132025386#comment-132025386)
I wrote my own flashcard program in college, it wouldn't surprise me if there were a dozen floating around in SIL. FileMaker Pro, used by Hayashi, Larry, is probably not the platform of choice, but I understand why he wrote it as a FileMaker user myself. If there is a need and nothing is being done, then we will have a whole group of amateur efforts to create something. Starting a project to do vocabulary well, then is not a reduplication of those efforts, because most of them wouldn't scale well or work across platforms. I happen to know that a Filemaker Pro runtime app takes about 100 Megabytes to install. So we need to talk with these users and find out which user they are trying to develop for, and what the gap is they are trying to fill.
Don't be so quick to criticize the process. I just went to the Phonology Assistant proposal and found that the following question was left blank:
What unique benefits will this project provide that are not provided by other alternatives? (e.g. problems solved, needs addressed, opportunities created, etc.)
It seems to me that this was specifically included to address duplication. The process is good, but somebody needs to reject proposals that don't do their homework.
Reply[Edit](https://wiki.insitehome.org/pages/editcomment.action?commentId=132025388&pageId=132023757\)[Delete]\(https://wiki.insitehome.org/pages/removecomment.action?commentId=132025388&pageId=132023757&atl_token=1bad93b270cf3693559d410e6c323ef84f403a55\) [Unlike](https://wiki.insitehome.org/pages/viewpage.action?spaceKey=%7EHUGH_PATERSON&postingDay=2014%2F4%2F17&title=Some+thoughts+about+the+Language+Software+Project+Proposal%3A+Vocabulary+Manager+6.0)
You and undefined like this [Apr 24, 2014](https://wiki.insitehome.org/display/%7EHUGH_PATERSON/2014/04/17/Some+thoughts+about+the+Language+Software+Project+Proposal%3A+Vocabulary+Manager+6.0?focusedCommentId=132025388#comment-132025388)
AUTHOR
That question, as I read it, focuses on what is distinguishing from other product, which is a necessary analysis. However, in the case of Dekreke and P.A. it is the features of these other applications which draws users away from the LSDev solution and towards "the competition". So, this kind of research on "why are potential or past users choosing not to use LSDev products?" needs to be captured too.
- Reply [Edit](https://wiki.insitehome.org/pages/editcomment.action?commentId=132874320&pageId=132023757\) [Delete](https://wiki.insitehome.org/pages/removecomment.action?commentId=132874320&pageId=132023757&atl_token=1bad93b270cf3693559d410e6c323ef84f403a55\)[Like]\(https://wiki.insitehome.org/pages/viewpage.action?spaceKey=%7EHUGH_PATERSON&postingDay=2014%2F4%2F17&title=Some+thoughts+about+the+Language+Software+Project+Proposal%3A+Vocabulary+Manager+6.0\) [Apr 24, 2014](https://wiki.insitehome.org/display/%7EHUGH_PATERSON/2014/04/17/Some+thoughts+about+the+Language+Software+Project+Proposal%3A+Vocabulary+Manager+6.0?focusedCommentId=132874320#comment-132874320)
Thanks for including a link to One-way Sync from XML (addon for Anki). Just to clarify: the reason I say "sync" rather than "export" is because (a) it doesn't generate duplicates every time it runs, (b) it flags items for deletion if deleted in the source, and (c) it preserves the non-lexical data in each flashcard (i.e. the card's history–how well the user knows it and thus how soon to show it again). Of course, most people think of "sync" as two-way (prototypically), which is why I emphasize the term "one-way" so much, and the warning that edits made in Anki will get overwritten. Syncing two-way between a flat record and a full-blown dictionary entry simply isn't feasible–at least not without turning Anki into a dictionary-editing tool.
- Reply [Edit](https://wiki.insitehome.org/pages/editcomment.action?commentId=132874719&pageId=132023757\)[Delete]\(https://wiki.insitehome.org/pages/removecomment.action?commentId=132874719&pageId=132023757&atl_token=1bad93b270cf3693559d410e6c323ef84f403a55\)[Unlike]\(https://wiki.insitehome.org/pages/viewpage.action?spaceKey=%7EHUGH_PATERSON&postingDay=2014%2F4%2F17&title=Some+thoughts+about+the+Language+Software+Project+Proposal%3A+Vocabulary+Manager+6.0\) You like this [Apr 25, 2014](https://wiki.insitehome.org/display/%7EHUGH_PATERSON/2014/04/17/Some+thoughts+about+the+Language+Software+Project+Proposal%3A+Vocabulary+Manager+6.0?focusedCommentId=132874719#comment-132874719)
Paterson, Hugh AUTHOR
Thanks Unknown User (jonathan_coombs) for the clarification. I think it is helpful when we consider the larger picture of the problem space we are trying to approach and provide solutions for to have these details.I am adding your comment from the email below as that is also helpful.
In case it's helpful to have a broad technical overview, here's what the tool I've been working on is/does:
- It's an addon written in Python for the popular open-source program, Anki (which is also written in Python, using PyQt for the GUI.) The addon's own interface is almost nonexistent--it consists mainly of a one-click menu item followed by a simple report of what was synced. If there were warnings/errors, the sync log is opened as well. (There are also a few "Yes/No/Cancel" dialogs during the initial configuration.)
- The idea is that the data is maintained in WeSay or FLEx, and the Anki flashcards are periodically updated based on the latest LIFT file. So, any edits made in Anki will be overwritten during sync. Existing flashcard history is preserved, however. Deletions in the source lexicon result in Anki cards being flagged for deletion (deleted media files are instead reported in the sync log as being obsolete; auto-delete is not yet implemented).
- Once the data is in Anki desktop, Anki itself has sync mechanisms for mobile and web that should work fine. But I've only tested with Anki desktop thus far.
- FLEx users must export to LIFT before each sync, but do not need to export their media files, as those can be pulled directly from the project folder.
- The one-way sync is configured via an XML file that contains a bunch of XPaths designed to extract data from an XML source file. Each XPath also says what to do with multiple values ("grab first" or "concatenate all"). So, the sync engine knows nothing about LIFT per se. Any straightforward XML source should work (if you configure it manually); FLEx's .fwdata format is too fragmented, however, since it's more like a relational database than a tree.
- The auto-config wizard is specific to LIFT; it knows just enough to take the default config for LIFT and tweak it to reflect your specific vernacular and analysis writing system. To really customize things (adding more writing systems, syncing custom fields, etc.), manually editing the config file is necessary.
- The default config recognizes two base objects: Entry and Example Sentence. (For entries with multiple senses, their fields will typically be forced into a single flat record by using concatenation.) If any example sentences are detected, auto config will offer to create one flashcard per example. If the user says Yes, then each sync will do two passes to collect source record data. I've provided two custom record types in Anki: DICT_LIFT and DICT_LIFT_EX with corresponding fields; adding more fields or even more types is straightforward if you don't mind editing an XML config file.
Anki works on Linux. Hopefully the addon will too, very soon.
The help file includes screenshots and details about config, but I thought an overview here might be useful.
- Reply[Edit](https://wiki.insitehome.org/pages/editcomment.action?commentId=132874731&pageId=132023757\)[Delete]\(https://wiki.insitehome.org/pages/removecomment.action?commentId=132874731&pageId=132023757&atl_token=1bad93b270cf3693559d410e6c323ef84f403a55\)[Like]\(https://wiki.insitehome.org/pages/viewpage.action?spaceKey=%7EHUGH_PATERSON&postingDay=2014%2F4%2F17&title=Some+thoughts+about+the+Language+Software+Project+Proposal%3A+Vocabulary+Manager+6.0\) [Apr 25, 2014](https://wiki.insitehome.org/display/%7EHUGH_PATERSON/2014/04/17/Some+thoughts+about+the+Language+Software+Project+Proposal%3A+Vocabulary+Manager+6.0?focusedCommentId=132874731#comment-132874731)
-
I'm including a thought from an email with Hugh.
I think VocabLift or something like it has real potential in the MLE space. Imagine a feature where, in this usecase, a teacher could select which languages to use in an education scenario involving a Computer Game
So for example, in the MSEA context: Should there be a LIFT file exported from a FLEx lexicon for the Lahu language which has both English and Thai Glosses, the teacher can select to have the front of the notecard be the Thai word with accompanying audio\visual files, and the back be the Lahu word. Of course the decks would have to be grade appropriate.