Archving FLEx Data
Any discussion about archiving needs to set out three things:
- What is it that is being archived.
- What is does it mean to "archive" as a process of activity.
- What is an archive.
The academic discussion around these three things is all over the map. Mostly because finding seekers are seeking to meet the requirements of institutions offering funding. The following discussion provides a road map and the dicsussion of all three elements listed above.
What is being archived?
FLEx is many things to many people. That is some use the software to maintain a list of words in the language being studied. Some people only use the parsig feature to parse texts. Others use FLEx to generate dictionaries, yet others use it to store texts as if were the final location those texts belonged. So when we talk about archiving FLEx we need to talk about it broadly as if the FLEx user was using it to store words, texts and relationships about words, and relationships about words in texts, and audio files and video files, and photos and the relationships of those media to the words. or texts.hile I suggest that FLEx databases are more than just dictionaries in database formats, a lot of the questions I have encountered from SIL users of FLEx who are looking to archive FLEx databases, have related to FLEx as a lexical resource. Therefore I want to look for a moment at the dichotomy of lexical resourceses.
1. All Lexical Resources
Linguists, archivists, and data wranglers all think in different terms (worldviews). It is an active act of translation to communicate the semantics, concepts and implications from one community to another community. For instance communicating to linguists what it means to archivists to archive a lexical resource, and communicating to data wranglers what resources are in the archive and how they are constructed. It is important to have this conversation so that as archivists and as linguists (submitters) we know where in the spectrum of lexical resources FLEx and Toolbox data sets fit.
Why do we need a typology of resource types?
Marketing of products (on the behalf of linguists and economic partners, including the matching of resources to SIL's services).
Communication between submitters and archivists.
Effective matching of metadata to other metadata systems.
The longevity (Data maintenance strategy) and upgrading of data formats. (Because these strategies are dependent on the data formats and the file types and the data resource types.)
The archive's (and LSDev too) audience (linguists) often think in terms of "the dictionary" or "the wordlist". This is an end product orientation. It has been well argued (by Steve Echerd, Gary Simons and others) that SIL would rather see their staff oriented towards "the lexical database" because that is the source. From such a source multiple end products can be produced. While it would be ideal to flip a switch and change these "linguist's" orientation, such a switch does not readily present itself. Therefore, the SIL services which deal with Lexical data must be clear, persuasive and educational in their communications.
With respect to the distinction between a lexical data set and an out-put end product like a "dictionary", the distinction must also be clear in the archiving records. That is, on the back end of the service to archive resources, the archive record's architecture and organization needs to reflect the derivative product relationships. Since there can be multiple derivative products per lexical data set, in a DSpace architecture, it seems that both objects should be items with a relationship "is_derivative_of" So, a dictionary item is_derivative_of the lexical data set item. This is discussed in section 1.3 below.
Linguists (especially American linguists) are trained deconstructionists. This means that one of their first questions is, _what do you mean by "lexical database" or "lexical data set"? _Clarifying for them what we mean is important as we strive to provide clear services to this class of consumers.
1.1 Resource Types
A consistent typology of lexical resources is challenging for several reasons. One of those reasons is that lexical resources are usually at the apices of several intersecting continuums. Some of these continuums are presented below.
| Wordlists | Encyclopedic entries |
|---|---|
| Monolingual | Poly-lingual |
| Non-Print (Oral) | |
| Single mode (i.e. textual only) | Multi-mode (i.e. text + audio, images, video) |
| Physical | Digital |
| Edited | Non-Edited |
| Single Author | Collaborative Production |
| Single IP | Multiple IP |
| Corpus Based | Non-Corpus Based |
Beyond these continuums there is also purpose both of data collection and of the out-put product. It is in this purpose that interactive ideal is established (linguists, like many other classes of individuals often leave this idea un stated). What do I mean by purpose? If we take the dictionary as an example, then there is the "Learner's dictionary", the "Bi-lingual dictionary", the "Picture dictionary", the "Domain specialist dictionary", etc.
1.2 Databases Types
Beyond the description of the thing-ness of lexical databases using the continuums above, there is the technical description of the database. We can talk about character sets (UTF-8, UTF-16, etc.), and we can also talk about the description of "the thing" by the application which we used to create "the thing". So it might be a ToolBox database or a FLEx database, etc. But even within these descriptions there issues like database schemas, or customizations which need to be documented if we are going to think about passing our data on to other users.
1.2.1 "The Things"
So, what is this "thing" we (linguists) need to actually submit to the archive? or the "thing" we (archivists) need to expect from linguists?
In a complete toolbox project file one should expect to find the following.
Some-zipped-toolbox-project.zip
├── .typ - File defining the database structure
├── .lng - File defining theLanguage encoding
├── .prj - Project file
└── Datafile - with one of the following file types
├── .db
├── .dic
├── null - meaning no file ending
├── .txt
└── .xml
In a complete FLEx 6 and previous project file one should expect to find the following.
-- Some tree of files and what those files represent or include and why
In a complete FLEx 7 and Newer project file one should expect to find the following.
-- Some tree of files and what those files represent or include and why
In a complete FLEx 8 and Newer project file one should expect to find the following.
-- Some tree of files and what those files represent or include and why
1.2.2 Are the same "Things" Equivalent?
Inter-version non-equivalence.
It follows then that as we look at various databases (For instance a FLEx database) as produced by various version of software (for instance FLEx 6 vs. FLEx 8) that the thing-ness of the digital object changes. This means from a reusability standpoint that the things are different. Notice that I am not talking about user changing the data in their databases over time, but rather I am talking about the technical composition of the object. This variation would suggest that the archive should have some method of grouping like "things" together. So, one should be able to get a report on all the "FLEx 6" databases or all the "FLEx 8" Databases.
Same version non-equivalence.
A second level of non-equivalence exists and may not be obvious to non-application users (especially archivists). To this point in the discussion we have been talking about FLEx and Toolbox databases and datasets as if they are only databases, or grids of words and their relationship to grammar and meaning. However, both applications can be used in multiple ways (and in deed are by various linguists). Let me take FLEx for instance, because it is more familiar to me (but in our communications with linguists we should provide examples from ToolBox and FLEx). A FLEx 8 database used by anthropologists may include texts, but rather than word level annotations about meaning and grammar, there are a plethora of annotations for notes on culture and anthropology (with very little marked in the database for grammar). This kind of FLEx database stands in contrast to the dictionary resource which is mostly focused on grammar and meaning.
However, the example of the anthropologist using FLEx with texts points to a larger challenge when considering and categorizing the output of tools like FLEx and ToolBox. That is, these tools are not just grids of words and meanings they also have texts in them. I refer to these texts as bit-text because they are in the written mode rather than in the oral or video mode. This pluralistic function of these resources is an important element to highlight and make available to discovery for linguists. In archiving terms it is as if the FLEx item contains other items which may not be archived independently. A FLEx database may have over 100 bit-texts which are parsed and glossed embedded inside of the "FLEx database". Therefore the kind of database which is based off of rapid word collection strategy is very different in terms of content from the database based off of bit-texts. When communicating the nature of the archived database with linguists this is an important element to communicate about. This is also an important element to realize for data transfer and an Archive's Data Preservation Strategy. In the transition from FLEx 7.2.7 to FLEx 8 I have seen no less than two discussions on the FLEx users group where data migration was botched because the texts were lost. The ability of FLEx to handle texts is also a point of critique by well established Toolbox users. That is, some ToolBox users either don't understand the current power of FLEx to process (bit-)texts, or they don't understand how to move (bit-)texts processed in ToolBox to FLEx, or ToolBox really is more flexible in processing (bit-)texts than FLEx. But both applications have bit-text elements, as well as grid-like elements.
1.3 The Archive Record
As previously discussed above, the archive record needs to consider the dictionary as an item but also the data used to create that dictionary. As we see in 1.2.2 bit-texts may be a part of that foundation. I think the crucial question to ask is: Is a dictionary a lexical database? are a lexical database and a dictionary the same thing? - If they are not then should they be put in the same record (Item) or should they be independent items with a relationship connecting them?
Archive Institution
└── DSpace
├── Community 1
│ ├── Collection 1
│ │ ├── Item 1
│ │ │ ├── Bitstream 1
│ │ │ └── Bitstream 2
│ │ └── Item 2
│ │ │ ├── Bitstream 1
│ │ │ └── Bitstream 2
│ └── Collection 2
└── Community 2
Once we have an answer to the Is a dictionary a lexical database? are a lexical database and a dictionary the same thing? question then we can move on to asking what does each record need to contain. In many respects this is like existing package development going on in ILPT for training resources and with respect to type-setters and the products and outputs they have.
1.3.1 What does an archive's catalogue entry for a dictionary need to look like?
Best practices for file archiving of Dictionaries in SIL's Archive. ( or What should the dictionary package include?)
- All dictionaries should have a lexical database associated with them.
- All dictionaries should have a PDF with them.
- All dictionaries should have the cover or jacket PDF (if one was created, if not then a comment to that effect should be in the description).
- All fonts and scripts used to format the lexical data into the PDF should be included.
- All dictionaries should have a write up of which materials in the Lexical database were included in the dictionary and how this was decided.
- All dictionaries with more than lexical content should include source files for those pages (portions) of the dictionary.
- All dictionaries with images should include the original source images in this archive package.
1.3.2 What does an archive's catalogue entry for a Lexical Data Set need to look like?
Best practices for file archiving of lexical databases in SIL's Archive. ( or What should the lexical database package include?)
All lexical data sets should have a write up explaining which custom fields are used and for what they are used. ****
All lexical data sets should have in their description the texts which are included in their texts portion. (These texts should also get their own item description.)
Not all lexical data sets have a dictionary output. All lexical datasets should have a .lift output. (even thought .lift is not everything in a FLEx dataset. - ie. LIFT it does not include bit-texts)
- All ShoeBox files should have_____ file ending
- A remark about SFM v.s MDF (the Schema used)
All ToolBox Files should have_____ file ending
- In all ToolBox files should be ______ components.
- A remark about SFM v.s MDF (the Schema used)
All FLEx databases should have_____ file ending
- All FLEx databases should have a remark about the FLEx version.
- What is included in a FLEx archived package?
- What is included in a FLEx back-up package?
- What is transferred to Language Depot? Is this the same as what is included in a FLEx Backup file?
- How long is data on Language Depot kept?
- Who owns the data on Language Depot?
- What is the license of the Data on Language Depot?
- Who has access to the files on Language Depot?
- Is Language Depot Use considered Archiving?
**** The guidance currently provided by the archive is really confusing because, as a surveyor, I could choose to put all my words collected in the FLEx database and because of my task goal it would be "complete" however, an encyclopedic lexicographer would not consider this complete. There are really two factors which I feel are trying to be answered by the single piece of guidance curently provided by the archive. 1st) Is the answer of coverage. It should be a statical feature of the application to be able to determine how many headwords are in the lexical database. Then the application should be able to look at those head words and determine how many fields are used for each lexical item. If the database has 1500 items, and on average each item has 5 other fields with data in it but across the database a total of 30 fields are uses with many of the 25 odd fields being used under 10 times, then the total database report should be able to quantify which files are used what percent of the time, and the complete list of named fields used. For instance 1500 head words, 1495 definitions, 1374 pronunciation fields, 1500 english glosses, 300 French glosses, 500 example sentences, etc. This is an example of coverage. However, Coverage is only one metric of "completeness" review and accuracy is also a metric. If we have only 300 items of those 1500 which have been reviewed by a second speaker, or a lexicography consultant then that is a separate part of this report, and it needs to be treated separately in instructions to those archiving lexical databases. By adding a stage meter to the entry level in architecture of FLEx we could then easily quarry the "average" stage of completeness or graph the state of the dataset by completeness: 300 entries consultant reviewed, 400 entires verified by more than one speaker, 800 entries in initial draft stage.Resource Types
A second thing to think about is data licensing --- talk here about the onion model
So, what is this "thing" we need to actually submit to the archive?
In a complete toolbox project file one should expect to find the following.
Some-zipped-toolbox-project.zip
├── .typ - File defining the database structure
├── .lng - File defining the Language encoding
├── .prj - Project file
└── Datafile - with one of the following file types
├── .db
├── .dic
├── null - meaning no file ending
├── .txt
└── .xml
In a complete FLEx 6 and previous project file one should expect to find the following.
In a complete FLEx 7 and Newer project file one should expect to find the following.
Is a dictionary a lexical database? are they the same thing? - If they are not then should they be put in the same record (Item) or should they be independent items with a relationship connecting them?
Archive Institution
└── DSpace
├── Community 1
│ ├── Collection 1
│ │ ├── Item 1
│ │ │ ├── Bitstream 1
│ │ │ └── Bitstream 2
│ │ └── Item 2
│ └── Collection 2
└── Community 2
What does a dictionary entry look like for archiving?
Best practices for file archiving of lexical databases and Dictionaries in SIL's Archive.
All dictionaries should have a lexical database associated with them.
All dictionaries should have a PDF with them.
All dictionaries should have the cover or jacket PDF.
All fonts and scripts used to format the lexical data into the PDF should be included.
All dictionaries should have a write up of which materials in the Lexical database were included in the dictionary and how this was decided.
All dictionaries with more than lexical content should include source files for those pages of the dictionary.
All ShoeBox files should have_____ file ending
All ToolBox Files should have_____ file ending
In all ToolBox files should be ______ components.
A remark about SFM v.s MDF
All FLEx databases should have_____ file ending
All FLEx databases should have a remark about the FLEx version.
Not all lexical data sets have a dictionary output. All lexical datasets should have a .lift output. (even thought .lift is not everything in a FLEx dataset.)
===Data maintenance strategy===
All Shoebox, ToolBox and FLEx databases should be archived one a year, at project's end and prior to conversion to another format (or version of)- like a FLEx database.
All Data conversion should be first attempted by the active project. All data from inactive projects should be updated annually with the release cycles of newer versions of FLEx. - This might could be scripted and conducted in the collaboration between the SIL Archive and the SIL Lexicography Data Conversion Service.
Lexical content Browser
Anatomy of archived lexical data sets
In a complete toolbox project file one should expect to find the following.
.zip
├── Database structure - .typ
├── Datafile - with one of the following file types
│ ├── .db
│ ├── .dic
│ ├── null - meaning no file ending
│ ├── .txt
│ └── .xml
├── Language encoding file - .lng
└── Project file - .prj
Last thing
Share the Questionnaire
Want to share the questionnaire with your community of linguists?
We are happy to help (or be helped as it were).
Below is the text we have been sending out.
Subject line
Lexical Database Archiving Questionnaire
Email Text Body
Last year the SIL Archive did an analysis of what kinds of materials are being submitted to SIL's Language and Culture Archive. During the 2012 year only 4 FLEx data sets were submitted to the archive (and about 6 Toolbox datasets). The archive is looking to see if this is a broader trend among linguists (and more generally lexical database users) or if it is unique to SIL contexts.
We are particularly expecting responses from people who work with minority languages but all lexicographic database users are open to respond to the Questionnaire. We are asking 4 questions and we estimate the whole thing takes about three minutes to complete:
If you are a creator or user of lexical databases (like Toolbox, FLEx, or Lexus, etc.):
Please take a quick moment to fill out the following online questionnaire: http://bit.ly/19QSPMb
Though
For those in a bandwidth restricted situation feel free to reply to the questions below with answers to: Hugh_Paterson [ at ] sil.org
Four questions:
What is your Lexical Database Management solution? Options generally include: FLEx, ToolBox, Lexus, other:____, etc :
- What is the ISO code of the language you are using it with?:
- Have you ever archived a version of your current Lexical Database at an official archive? (An archive like SIL's L & CA -REAP-, or SOAS's ELAR, or MPI's TLA, or PARADISEC. - Though it doesn't have to be one of these four. ) - Yes / No:
4: Have you ever produced a Print or Digital Publication from your Lexical data (like a Glossary or a Dictionary)? if so we would like to hear about it, got a link or a citation?:
One entry per language. If you work with more than one language, feel free to submit one answer per language or add a comment to that effect with a list of the ISO 639-3 codes or language names.
Personal details (email address and name) will be kept confidential, other data and generalizations of trends may be published.
Thank you for the work you do and the effort you make to serve speakers of minority languages.
- Created by Paterson, Hugh
Unlike the title of this post, the following use case is not written in satire. It is a conversation I have had with PARADISEC, an archive in Australia. I have copied over the raw email transcripts. Note, the names have not been changed to protect the guilty. I hope that by sharing this dialog internally in SIL circles that critical players in SIL publicity, SIL communications strategy, and SIL product development, will come to understand that SIL needs to take a more active role in helping language archives understand the kinds of language artifacts that are being created by SIL's tools and methods, and how to effectively archive those artifacts - including any data migration strategies needed to update materials to make them useable with current tools (or current versions of the same tool).
An email to the collections manager of PARADISEC and to the depositor. The item in question has a creation date somewhere around 2010-2011.
Greetings,
I was browsing, the Papuan Languages Collection in which the following item is a part:
http://catalog.paradisec.org.au/collections/DD1/items/028
. I noticed that some of the FLEx databases were turned over to the archive as .zip files. However, the files listed in the file list for the parts of the collection are .xml files. I know that FLEx can export .xml LiFT files, but I also know that FLEx can export "project backups". In the "project backups" there is sometimes more data including texts and parsing rules created by FLEx. Therefore these "project backups" can contain more information than just the LiFT file contains. Which was submitted to the archive? LiFT .xml files or the "export/ Project Backup"? and if it was "export/ Project Backup" does this mean that the archive (PARADISEC), "unziped" the backup file before putting the content in its archive?
thanks for the clarification,
- Hugh Paterson III
Reply from the PARADISEC collections manager.
Dear Hugh,
This is really a question for the depositor so I hope Don will chime in. We prefer to have the most open and accessible version of the material we can. But, as we are not resourced to examine all content as it comes in, we rely on the depositor to create the best archival version of their materials. Zip and other compressed formats are not suitable for archiving, but text (including XML) is fine.
All the best,
Nick Thieberger
Reply from Don Daniels the depositor,
Hi Hugh and Nick,
The files I archived were old FLEx backups (made with version 6 or 7, probably), back when the program created a .zip file. When PARADISEC received them, they unzipped them and archived the .xml file that was inside. If there was any other information in the original .zip files, I don't know what happened to it. I'm actually preparing new databases for archiving, though, so this will all be moot soon enough. The new files will be created with FLEx 8, which creates its own file type (.fwbackup, I believe), and I don't expect those will be changed.
Best,
Don
Finally my final reply,
Thanks Don,
This is what I suspected had happened. I was actually looking for a use case for an upcoming discussion I am having with the lexicography and software teams at SIL. It is interesting how generally safe assumptions about .zip files being unsuitable for archiving actually can cause archivists to weaken the integrity of the objects entrusted to their archives. Not that the FLEx website, or SIL in general makes this point about .zip files being the most suitable format for archiving FLEx databases at all clear. My understanding is that there is indeed more in the .zip file of those older FLEx backup files. I think texts, parsing rules, and keyboard files could also have been in there.
As a FLEx 8 user, I trust you already realize that there is more contained in a ".fwbackup" than there is in the LiFT .xml exports. Again my understanding is that texts, parsing rules, media associated with the lexical entry, and keyboard files could also be in the .fwbackup but will not be present in the LiFT.xml export file (and the LiFT export file might even contain a limited set of the total entries based on any filters active when the export is made).
Anyways, thank you for clarifying this unfortunate, but hopefully, useful case. I plan on taking it back to SIL to start a much needed discussion about how archives (including SIL's own archive) can respect the "thing-ness" of the variations in FLEx databases when the application changes versions.
- Hugh Paterson III
One interesting element about this discussion is that I have heard the SIL Language and Culture Director say that if an SIL team is using LanguageDepot that they don't need to archive their lexical database in REAP because the content is already on "SIL data stores". However, my understanding of Language Depot limitations is that media, over 1 MB are not uploaded to LanguageDepot, texts which are stored in FLEx are not uploaded to LanguageDepot, Parsing rules and Keyboard are also not uploaded to LanguageDepot. In my mind this makes the content on language Depot, and the content of a .fwbackup file significantly different. Enough different to not qualify as an "archived" version of the lexical database. Additionally, Data permissions which may include permissions from speakers are not included in content on LanguageDepot, where there are mechanisms for the licensing and permissions of data via REAP.
1. All Lexical Resources
Linguists, archivists, and data wranglers all think in different terms (worldviews). It is an active act of translation to communicate the semantics, concepts and implications from one community to another community. For instance communicating to linguists what it means to archivists to archive a lexical resource, and communicating to data wranglers what resources are in the archive and how they are constructed. It is important to have this conversation so that as archivists and as linguists (submitters) we know where in the spectrum of lexical resources FLEx and Toolbox data sets fit.
Why do we need a typology of resource types?
Marketing of products (on the behalf of linguists and economic partners, including the matching of resources to SIL's services).
Communication between submitters and archivists.
Effective matching of metadata to other metadata systems.
The longevity (Data maintenance strategy) and upgrading of data formats. (Because these strategies are dependent on the data formats and the file types and the data resource types.)
The archive's (and LSDev too) audience (linguists) often think in terms of "the dictionary" or "the wordlist". This is an end product orientation. It has been well argued (by Steve Echerd, Gary Simons and others) that SIL would rather see their staff oriented towards "the lexical database" because that is the source. From such a source multiple end products can be produced. While it would be ideal to flip a switch and change these "linguist's" orientation, such a switch does not readily present itself. Therefore, the SIL services which deal with Lexical data must be clear, persuasive and educational in their communications.
With respect to the distinction between a lexical data set and an out-put end product like a "dictionary", the distinction must also be clear in the archiving records. That is, on the back end of the service to archive resources, the archive record's architecture and organization needs to reflect the derivative product relationships. Since there can be multiple derivative products per lexical data set, in a DSpace architecture, it seems that both objects should be items with a relationship "is_derivative_of" So, a dictionary item is_derivative_of the lexical data set item. This is discussed in section 1.3 below.
Linguists (especially American linguists) are trained deconstructionists. This means that one of their first questions is, _what do you mean by "lexical database" or "lexical data set"? _Clarifying for them what we mean is important as we strive to provide clear services to this class of consumers.
1.1 Resource Types
A consistent typology of lexical resources is challenging for several reasons. One of those reasons is that lexical resources are usually at the apices of several intersecting continuums. Some of these continuums are presented below.
| Wordlists | Encyclopedic entries |
|---|---|
| Monolingual | Poly-lingual |
| Non-Print (Oral) | |
| Single mode (i.e. textual only) | Multi-mode (i.e. text + audio, images, video) |
| Physical | Digital |
| Edited | Non-Edited |
| Single Author | Collaborative Production |
| Single IP | Multiple IP |
| Corpus Based | Non-Corpus Based |
Beyond these continuums there is also purpose both of data collection and of the out-put product. It is in this purpose that interactive ideal is established (linguists, like many other classes of individuals often leave this idea un stated). What do I mean by purpose? If we take the dictionary as an example, then there is the "Learner's dictionary", the "Bi-lingual dictionary", the "Picture dictionary", the "Domain specialist dictionary", etc.
1.2 Databases Types
Beyond the description of the thing-ness of lexical databases using the continuums above, there is the technical description of the database. We can talk about character sets (UTF-8, UTF-16, etc.), and we can also talk about the description of "the thing" by the application which we used to create "the thing". So it might be a ToolBox database or a FLEx database, etc. But even within these descriptions there issues like database schemas, or customizations which need to be documented if we are going to think about passing our data on to other users.
1.2.1 "The Things"
So, what is this "thing" we (linguists) need to actually submit to the archive? or the "thing" we (archivists) need to expect from linguists?
In a complete toolbox project file one should expect to find the following.
Some-zipped-toolbox-project.zip
├── .typ - File defining the database structure
├── .lng - File defining theLanguage encoding
├── .prj - Project file
└── Datafile - with one of the following file types
├── .db
├── .dic
├── null - meaning no file ending
├── .txt
└── .xml
In a complete FLEx 6 and previous project file one should expect to find the following.
-- Some tree of files and what those files represent or include and why
In a complete FLEx 7 and Newer project file one should expect to find the following.
-- Some tree of files and what those files represent or include and why
In a complete FLEx 8 and Newer project file one should expect to find the following.
-- Some tree of files and what those files represent or include and why
1.2.2 Are the same "Things" Equivalent?
Inter-version non-equivalence.
It follows then that as we look at various databases (For instance a FLEx database) as produced by various version of software (for instance FLEx 6 vs. FLEx 8) that the thing-ness of the digital object changes. This means from a reusability standpoint that the things are different. Notice that I am not talking about user changing the data in their databases over time, but rather I am talking about the technical composition of the object. This variation would suggest that the archive should have some method of grouping like "things" together. So, one should be able to get a report on all the "FLEx 6" databases or all the "FLEx 8" Databases.
Same version non-equivalence.
A second level of non-equivalence exists and may not be obvious to non-application users (especially archivists). To this point in the discussion we have been talking about FLEx and Toolbox databases and datasets as if they are only databases, or grids of words and their relationship to grammar and meaning. However, both applications can be used in multiple ways (and in deed are by various linguists). Let me take FLEx for instance, because it is more familiar to me (but in our communications with linguists we should provide examples from ToolBox and FLEx). A FLEx 8 database used by anthropologists may include texts, but rather than word level annotations about meaning and grammar, there are a plethora of annotations for notes on culture and anthropology (with very little marked in the database for grammar). This kind of FLEx database stands in contrast to the dictionary resource which is mostly focused on grammar and meaning.
However, the example of the anthropologist using FLEx with texts points to a larger challenge when considering and categorizing the output of tools like FLEx and ToolBox. That is, these tools are not just grids of words and meanings they also have texts in them. I refer to these texts as bit-text because they are in the written mode rather than in the oral or video mode. This pluralistic function of these resources is an important element to highlight and make available to discovery for linguists. In archiving terms it is as if the FLEx item contains other items which may not be archived independently. A FLEx database may have over 100 bit-texts which are parsed and glossed embedded inside of the "FLEx database". Therefore the kind of database which is based off of rapid word collection strategy is very different in terms of content from the database based off of bit-texts. When communicating the nature of the archived database with linguists this is an important element to communicate about. This is also an important element to realize for data transfer and an Archive's Data Preservation Strategy. In the transition from FLEx 7.2.7 to FLEx 8 I have seen no less than two discussions on the FLEx users group where data migration was botched because the texts were lost. The ability of FLEx to handle texts is also a point of critique by well established Toolbox users. That is, some ToolBox users either don't understand the current power of FLEx to process (bit-)texts, or they don't understand how to move (bit-)texts processed in ToolBox to FLEx, or ToolBox really is more flexible in processing (bit-)texts than FLEx. But both applications have bit-text elements, as well as grid-like elements.
1.3 The Archive Record
As previously discussed above, the archive record needs to consider the dictionary as an item but also the data used to create that dictionary. As we see in 1.2.2 bit-texts may be a part of that foundation. I think the crucial question to ask is: Is a dictionary a lexical database? are a lexical database and a dictionary the same thing? - If they are not then should they be put in the same record (Item) or should they be independent items with a relationship connecting them?
Archive Institution
└── DSpace
├── Community 1
│ ├── Collection 1
│ │ ├── Item 1
│ │ │ ├── Bitstream 1
│ │ │ └── Bitstream 2
│ │ └── Item 2
│ │ │ ├── Bitstream 1
│ │ │ └── Bitstream 2
│ └── Collection 2
└── Community 2
Once we have an answer to the Is a dictionary a lexical database? are a lexical database and a dictionary the same thing? question then we can move on to asking what does each record need to contain. In many respects this is like existing package development going on in ILPT for training resources and with respect to type-setters and the products and outputs they have.
1.3.1 What does an archive's catalogue entry for a dictionary need to look like?
Best practices for file archiving of Dictionaries in SIL's Archive. ( or What should the dictionary package include?)
- All dictionaries should have a lexical database associated with them.
- All dictionaries should have a PDF with them.
- All dictionaries should have the cover or jacket PDF (if one was created, if not then a comment to that effect should be in the description).
- All fonts and scripts used to format the lexical data into the PDF should be included.
- All dictionaries should have a write up of which materials in the Lexical database were included in the dictionary and how this was decided.
- All dictionaries with more than lexical content should include source files for those pages (portions) of the dictionary.
- All dictionaries with images should include the original source images in this archive package.
1.3.2 What does an archive's catalogue entry for a Lexical Data Set need to look like?
Best practices for file archiving of lexical databases in SIL's Archive. ( or What should the lexical database package include?)
All lexical data sets should have a write up explaining which custom fields are used and for what they are used. ****
All lexical data sets should have in their description the texts which are included in their texts portion. (These texts should also get their own item description.)
Not all lexical data sets have a dictionary output. All lexical datasets should have a .lift output. (even thought .lift is not everything in a FLEx dataset. - ie. LIFT it does not include bit-texts)
- All ShoeBox files should have_____ file ending
- A remark about SFM v.s MDF (the Schema used)
All ToolBox Files should have_____ file ending
- In all ToolBox files should be ______ components.
- A remark about SFM v.s MDF (the Schema used)
All FLEx databases should have_____ file ending
- All FLEx databases should have a remark about the FLEx version.
- What is included in a FLEx archived package?
- What is included in a FLEx back-up package?
- What is transferred to Language Depot? Is this the same as what is included in a FLEx Backup file?
- How long is data on Language Depot kept?
- Who owns the data on Language Depot?
- What is the license of the Data on Language Depot?
- Who has access to the files on Language Depot?
- Is Language Depot Use considered Archiving?
**** The guidance currently provided by the archive is really confusing because, as a surveyor, I could choose to put all my words collected in the FLEx database and because of my task goal it would be "complete" however, an encyclopedic lexicographer would not consider this complete. There are really two factors which I feel are trying to be answered by the single piece of guidance curently provided by the archive. 1st) Is the answer of coverage. It should be a statical feature of the application to be able to determine how many headwords are in the lexical database. Then the application should be able to look at those head words and determine how many fields are used for each lexical item. If the database has 1500 items, and on average each item has 5 other fields with data in it but across the database a total of 30 fields are uses with many of the 25 odd fields being used under 10 times, then the total database report should be able to quantify which files are used what percent of the time, and the complete list of named fields used. For instance 1500 head words, 1495 definitions, 1374 pronunciation fields, 1500 english glosses, 300 French glosses, 500 example sentences, etc. This is an example of coverage. However, Coverage is only one metric of "completeness" review and accuracy is also a metric. If we have only 300 items of those 1500 which have been reviewed by a second speaker, or a lexicography consultant then that is a separate part of this report, and it needs to be treated separately in instructions to those archiving lexical databases. By adding a stage meter to the entry level in architecture of FLEx we could then easily quarry the "average" stage of completeness or graph the state of the dataset by completeness: 300 entries consultant reviewed, 400 entires verified by more than one speaker, 800 entries in initial draft stage.
A second thing to think about is data licensing --- I talk here about the onion model. (in the comments on that page, do a search for 'onion') I would like to clean up and clarify those ideas as I bring them into this discussion.
As a cursory remark each contributor to the data set contained in a Flex database may not also be a contributor to a dictionary produced from those data sets. This means that contributors, their roles and their contribution need to be tracked within the data base and a means for attribution at each node within the data model needs to be available.
What does a lexical dataset description need to look like?
- Number of entries
- Level of editing
- Date of active range collection
- Name of language input editor
- Name of contributors and their general contributions "tom added head words"; "sue added example sentences", etc.
- If content is derived from text then citations to those texts
- SFM or data structure used (MXB style SFM data structure is different from Philippines data structure.)
=== Data Maintenance Strategy ===
All Shoebox, ToolBox and FLEx databases should be archived once a year, at project's end and prior to conversion to another format (or version of)- like a FLEx database.
All Data conversion should be first attempted by the active project. All data from inactive projects should be updated annually with the release cycles of newer versions of FLEx. - This might could be scripted and conducted in the collaboration between the SIL Archive and the SIL Lexicography Data Conversion Service.
Lexical content Browser
What does Versions mean in a REAP context as apposed to a language depot context?
=== Clear communication about services ===
Explain the relationship between Webonary and Archiving
Explain the relationship between Language Depot and Archiving
Explain the relationship between Language Depot and Webonary
Explain how one becomes a client of the Language and Culture Archive
How does one becomes a client of the Language and Culture Archive?
- Anyone can request content from the archive via sil.org mechanisms.
- Only SIL Members may submit content to be archived.
Contracted Archiving Services
- If collegial organizations or partner organizations (and their staff) want to archive their own content at SIL's repository (REAP) then an MOU with the Language and Culture Archive must be signed, then special collections and arrangements are created for these organizations and their staff (see here for more details).
Who is Eligible to use the service?
- Anyone can request content from the archive and browse archive listings from sil.org
- Archive listings to persons with insite access may browse listings directly in REAP (the advantage over using SIL.org is that additional listings may be available which are not suitable for public access via sil.org)
- Only SIL Members and staff of organizations with active archiving services contracts may submit content to be archived
Cost?
- Cost is currently free for SIL Members
- Fee structures for staff of organizations with contracted archiving services are available through the client organization.
What data is needed?
How is content submitted?
- Via RAMP: http://ramp.insitehome.org
Who owns the data?
The author, compiler or editor continues to own the data.
- If the work was done as work-for-hire, then the hiring organization also has a claim on the work (Currently, the SIL model is that if work was completed as part of an SIL assignment then SIL owns the data, because that person was doing work-for-hire for SIL.)
What is accessible to whom?
- Does a submitter have continued access to submissions even if they leave SIL or change roles within SIL?
- SIL Reserves the Right to control access to data regardless of who is the data owner. SIL may move content from open access to restricted access at any time pursuant to its business interests.
What happens to the data when service users submit their data to the service providers? and what happens to the data when the service request is filled?
What is the expectation for Data Maintenance or preservation? (transmission to new data formats, to keep data current)
Explain how one becomes a client of the data conversion service offered by the Lexicography Service Group.
- Who is Eligible to use the service?
- Cost?
- What data is needed?
- What is accessible to whom?
- What happens to the data when service users submit their data to the service providers? and what happens to the data when the service request is filled?
Explain how one becomes a client or user of Language Depot.
- Who is Eligible to use the service?
- Cost?
- What is uploaded?
- What is accessible to whom?
- How is this different than a FLEx Back-up?
Explain how one becomes a client of the Webonary service.
- Who is Eligible to use the service?
- Cost?
- What is uploaded?
- What is accessible to whom?
- How is this different than a FLEx Back-up?
2. Explaining Archived Resources
2.1 Un-archived Resources
May be:
- known (common knowledge, grant funded, etc.)
- unknown (e.g. individual research projects, that only select few know to exist)
- discoverable (posted on a personal or departmental website)
- privately kept (without public discovery)
However, no instance (and therefore also record) of these resources exists in the curated catalogues of professional libraries or institutional archives dedicated to the care and stewardship of language resources. Furthermore, in the above scenarios there is no long term preservation plan for these resources, even if a redundancy fallback copy of the data exists.
2.2 Archived but Private Resources
Private resources are severely restricted. Most people (including specialists in the language family, some archive staff and even some community members) do not know about them.
- Meta-data is hidden (not shared publicly).
- Archived objects have restricted access.
While archives may not be able to directly report on these objects, they can indirectly report what percentage of the archive's total content these items comprise.
2.2.1 Reporting on Private Resources
Example of an indirect report: 10% of XYZ archive's total contents are severely restricted. Most corpora in the archive contain less than 0.1% of severely restricted content.
Such reporting is healthy for:
- Funders
- to help understand the nature of how language data is viewed by various communities. It also communicates that the archiving institution is being as transparent as possible with the data it does have - a mark of faithful stewardship.
- Archive administrators
- to monitor basic trends across individual corpora (language projects or submission sets), across their entire archive's submissions, and across the larger language archiving community.
- Language and linguistic specialists
- to realize that these options do exist and if these options need to be exercised, that these options for archiving are used within industry "norms". To this end, linguists also need some example use cases.
- Communities
- to realize that archives have not forgotten that they have a connection with communities which are not listed in more public places.
Some restrictions are necessary. They help to build trust in archiving institutions and appropriate expectations for various stakeholders.
Note: The reasons for these restrictions should be documented so that when archive staff change, the rational for the restrictions is not lost. Additionally, the archive staff and the depositors should be in contact at a pre-determined interval to establish the continued necessity for this level of resource suppression. Frequency of communication can vary (but 3-5 years is a long time in today's world). Additionally communication about the contents of any collection or restricted collection should not be dependent upon the depositor.
2.3 Archived but Restricted Resources
Meta-data is publicly advertised via a clean navigable website, is discoverable to industry leading search engines, and through specific archiving and linguistic industry standard venues like OLAC. In contrast the the high visibility of the meta-data, the archived objects have restricted (permissions based) access.
- Meta-data is open and discoverable.
- Items have restricted access.
To maintain trust in this context, items should have: a stable endpoint (URI address) for citation purposes and a contact method for requesting access to the item (not necessarily the whole corpus). Resource items also need to be able to display their relationship to (1) the corpus as a whole and (2) other items in the corpus (especially those which are needed to function together). Additionally, archives should have in place a stewardship protocol granting them authority to administer the deposits in such cases that the original depositor is disinclined to remain alive or in contact with the archive.
2.4 Archived and Open Resources
Meta-data is publicly advertised, and the resource is openly available.
- Meta-data is open, discoverable and shareable under open licenses.
- Items are open to public access either through direct click and download or through an automated human verification (like login or recaptcha).
2.5 License and Access are not the same.
Creative Commons or CC0 data may be housed by the archive but not made accessible. An archive may choose to not share data even if the data was freely received and the archive has permission to share the data freely. SIL only shares items in manners which meet strategic goals. If it is strategic to not share an item then that item will not be made accessible regardless of the license applied to the item. This may mean that there can be a growing class of items which are "open" (by license) but not "available" (by access).
3. Clarifying and differentiating Archiving from other activities
3.1 What is the difference between archiving and back-up?
Short answer: Back-up protects us from data-loss, whereas archiving inducts the data into practices of: data preservation, formal description, systematic access, and data protection.
Archiving and Back-up are different.
First lets explain what we mean by, "Copy" and "Back-up" and then we will contrast this with what we mean by "Archive". In the IT industry there are generally three kinds of Back-up (explained below). Additionally, we often see the word "archive" associated with IT products. e.g. Google Mail (Gmail) has a feature called "archive", as do many IMAP email systems. Amazon Cloud Storage promotes their some of their data storage products as being "good for 'archiving'". We take issue with how the term is used in these contexts and clarify what we mean by archiving below.
'Copy' and 'Back-up'
- Same Drive - Onsite :: we call this a Copy . - If your computer is stolen or the drive goes bad both "copies" are lost. This is not a back-up.
- Separate Drive - Onsite :: This is where a copy of the data lives on a second drive, but the drive is in the same location as you computer where the file exists. If one of the two drives dies then the data is recoverable from the second drive. However, because both drives are in the same location, it is highly probable that if there was a catastrophic event: Fire, Explosion (war), or theft, that both devices would be rendered unusable. An example of this kind of back-up solution for OS X is Time-Machine.
Separate Drive - Offsite
:: This kind of back-up solution may come in two varieties: (1) Same Region or (2) Different Region.- Same Region works like this: The person backing things up takes the drive and makes a back-up copy and passes the drive off to a custodian who stores the drive (and data) entrusted to them in a secondary location in some other part of the city or small country. Often for this to work well, it must be done at regular intervals. In one language documentation project Hugh Paterson was involved in he used Time-Machine and replaced data on the offsite disk weekly. - Note : many linguistic field projects, including SIL entities around the world have solutions at this level.
- Different Region works like this: The person backing things up (usually) uses a dynamic service which stores a copy of their hard drive in one or more data centers. There are several commercial services which work like this but all function slightly different. For example: CrashPlanPROe, Carbonite. At this level of back-up solution, if a datacenter in a hurricane zone like Florida was destroyed, then the data would be expected to be stored somewhere else like Los Angles, or Tokyo. The data could then be restored or accessed from this second location.
Note: What about Google Drive, Sugar Sync, or DropBox aren't these back-up solutions? No. We would not classify these as back-up solutions. We classify them as collaboration and file sharing solutions. Here is why: when these kinds of solutions are used they, (typically) sync materials from your computer to the user's cloud account. If a user accidentally deletes their content from their computer then this deletion is also replicated to these remote file stores. Thereby also deleting the file in the offsite location. (We recognize that some services do offer versioning which does give users limited capability to recover deleted files, but these features are not automatic, and usually come bundled with premium version of these products/services.)
So then what does 'Archived' mean and how is it different from 'Back-up'? - Whereas back-up is primarily concerned with data loss prevention, Archiving is concerned with preservation of usability (of the data), discoverability, provenance (history) and identification (of the data), and then also access to data.
3.2 If my Data is in the cloud does that mean it is archived?
This is also a great question, because there are a lot of issues involved with cloud data. First cloud data is often social, and implies variation though versions (updates or changes to the same dataset) and forks (dataset splits where each set is then modified independently). Second cloud data is not on the local machine and therefore can feel to some like an "offsite back-up" solution.
With regards to lexical datasets SIL offers two independent cloud services:
- languagedepot.org
- A web service which enables the send and receive functions of lexical dataset building teams to share their data with each other through FLEx's built in Send/Receive function.
- webonary.org
- A website where FLEx data can be hosted and viewed.
- Additionally, some linguists and lexical data user use third party services like github.com or bitbucket to host their data so they can communicate with with collaborators.
http://en.wikipedia.org/wiki/Gnolia
http://www.wired.com/business/2009/01/magnolia-suffer/
First lets address the cloud - What is the cloud is the data secure? (and secure from what)
social data and the iterative nature of lexical resources. There are lots of tools like DropBox, SugarSync, Google Drive, etc. These are not necessarily even successful back-up strategies.
4. Specific Objections and Confusion surrounding Archiving, SIL's Cloud based services, and FLEx
and some answers to those objections
SIL Member says:
(1) Did you want me to archive my data? I have never been asked to do so, or given any instructions on how.
(2) I tried transferring my data from toolbox to FLEx, but my branch is actually a small group with no technical department (and I was not in the country at the time), and my sending organisation was too short of expertise to help me. I got by, but I wonder if other members are hampered by lack of technical assistance, or if it was just me.
SIL Member says:
Note re why the dataset was not uploaded to REAP: I intended to upload them to REAP, but when I started to do that a couple of years ago, I did not know whether just the downloadable files should be in REAP or the entire website. At that time, there were no instructions in REAP about how to archive web sites. I then wrote to Laurie Nelson the REAP administrator and the matter of how to archive web sites with lexical data was taken on my others. Only just recently have the PDF files of the print publication been archived in REAP.
SIL Member says:
Since it was submitted to SIL for e-publication and is online with Webonary.org, I assumed that it was de facto archived. If not, what should I do?
SIL Member says:
I have posted a version of the dictionary on the web. Reason the lexical database is not archived is because it is never finished - still in process.
SIL Member says:
What counts as an "SIL" project?
SIL Member says:
Just tried to use FLEx couple of times, but it's really working too slow for real work (20.000+ entry dictionary).
SIL Member says:
The project is on Language Depot for purposes of collaboration.
I have an appointment tomorrow to begin archiving my language materials on REAP. I made the appointment before receiving your email.
Non-SIL Member says:
I tried migrating from Toolbox to Flex but the lack of sufficient fields in the text function of Flex discouraged me from continuing.
Non-SIL Member Says:
I am also using ELAN for annotating video recordings. I would like to export files for analysis from ELAN to FLEx, but don't have enough experience. I also want to export earlier Toolbox files to FLEx but have problem in doing that.
Non-SIL Member says:
I like FLEx, but wish there were more developers on the coding side of the the tool. There are a lot of great things that just need small tweaks but are not completed because of the queue of features being added.
Non-SIL Member says:
While we have not yet archived the FLEx database, we do intend to once work has progressed a little further - it is still in the early stages. The database will be archived with PARADISEC. Print publications are also planned, at least for community circulation, but again these will not happen until we have more data.
Non-SIL Member says:
I am currently using Toolbox and am happy with it. But I would not mind giving FLEX a go, however, I am unable to locate a handbook or manual for the software to get started. Do you have one? I am also currently using three parallel linked dictionaries in Toolbox (multilingual Northern Australian environment) and I am not sure if this is also possible in FLEX?
5. Understanding the Results of Hugh's Lexical Database Archiving survey
5.1 Context of the survey
The Impetus:
Hugh was looking at several issues and realized that clearer communication with end users about SIL's services and products and their interrelationships would benefit end users and likely have positive effects on SIL service offerings. Hugh was particularly interested in how digitally delivered training and helps could be delivered online for various digital tools which SIL produces. The survey developed was focused at tool users (both SIL and non-SIL users). Hugh created the questionnaire and then chose Google forms to collect data. After seeing the results it became clear that several of SIL's service groups might benefit from the results.
How it was presented to Participants:
The following paragraph (or something close to it) was at the header of the invite to participate in the questionnaire.
Hugh Paterson III, in cooperation with Jeremy Nordmoe of the SIL Language and Culture Archive, is investigating the trend among lexical database users to archive their work. In their poster presented at ICLDC3, it was claimed that less than 1% of SIL projects archive lexical datasets. Hugh and Jeremy want to know if this is common among all lexical database users or just SIL users of FLEx & ToolBox.
5.2 Value of the results to SIL Organizational Units
LSDev - The open ended and un filtered contents show a strong desire of respondents to be able to migrate their data from ToolBox to FLEx. The Pathways to do this are not very clear to the user group.
Lexicography Services Group
- This list of respondents should be of interest for two reasons (1) these are the people who need (and sometimes even want) help via the data migration service, and (2) These are the people who are candidates for the webonary service.
Communications
- How are we communicating about SIL policies, SIL services and SIL products. The great many respondents with questions and lack of clarity should be an indicator to our success or failure in communication.
ILPT
- How are people connected with the training elements surrounded with our various products and services. The level of confusion displayed with these comments should be an indicator in our success or failure in accessibility and consumption of training resources.
Language & Culture Archive
- Are people really archiving? No. they are not. But they have some interesting mis-understandings about (1) the reason for archiving, (2) what it is, (3) how to do it, (4) what to archive.
5.3 Data from the survey
Those who responded said that they work on languages which SIL.org says are from the following places. Dots of any kind represent the languages which are being described in the lexical databases. Blue and Yellow dots are respondent identified SIL projects. Green and Red dots are respondent identified non-SIL projects, or projects where this information was not provided. Red and Yellow dots are "endangered languages" according to SIL.org, while Blue and Green dots are "robust languages" according to SIL.org
Software and version can make a lot of difference in opinions about the usefulness of completing tasks.
This is a graph of the kinds of responses about software versions received through the survey. The launch of this questionnaire unintentionally coincided with the launch of FLEx 8. So, FLEx users may be a moving target. However, note that some go as far back as FLEx 6 and often users do not like to "upgrade" during a "project" - much like how students aviod installing a new OS while doing a thesis.
SIL Entity participation
For some reason MSEAG was the only SIL entity which actively requested that I not connect with their teams, and that they would not support the propagation of the survey questionnaire. The most supportive of the questionnaire were SIL PNG, SIL Nigeria Group and SIL Mexico Branch who connected me with appropriate staff directly or propagated the questionnaire on my behalf and returned the results to me. Other entities were were either passive or non-interactive - Individuals from a variety of unnamed entities participated on an individual basis. The survey is still open so things could still change.
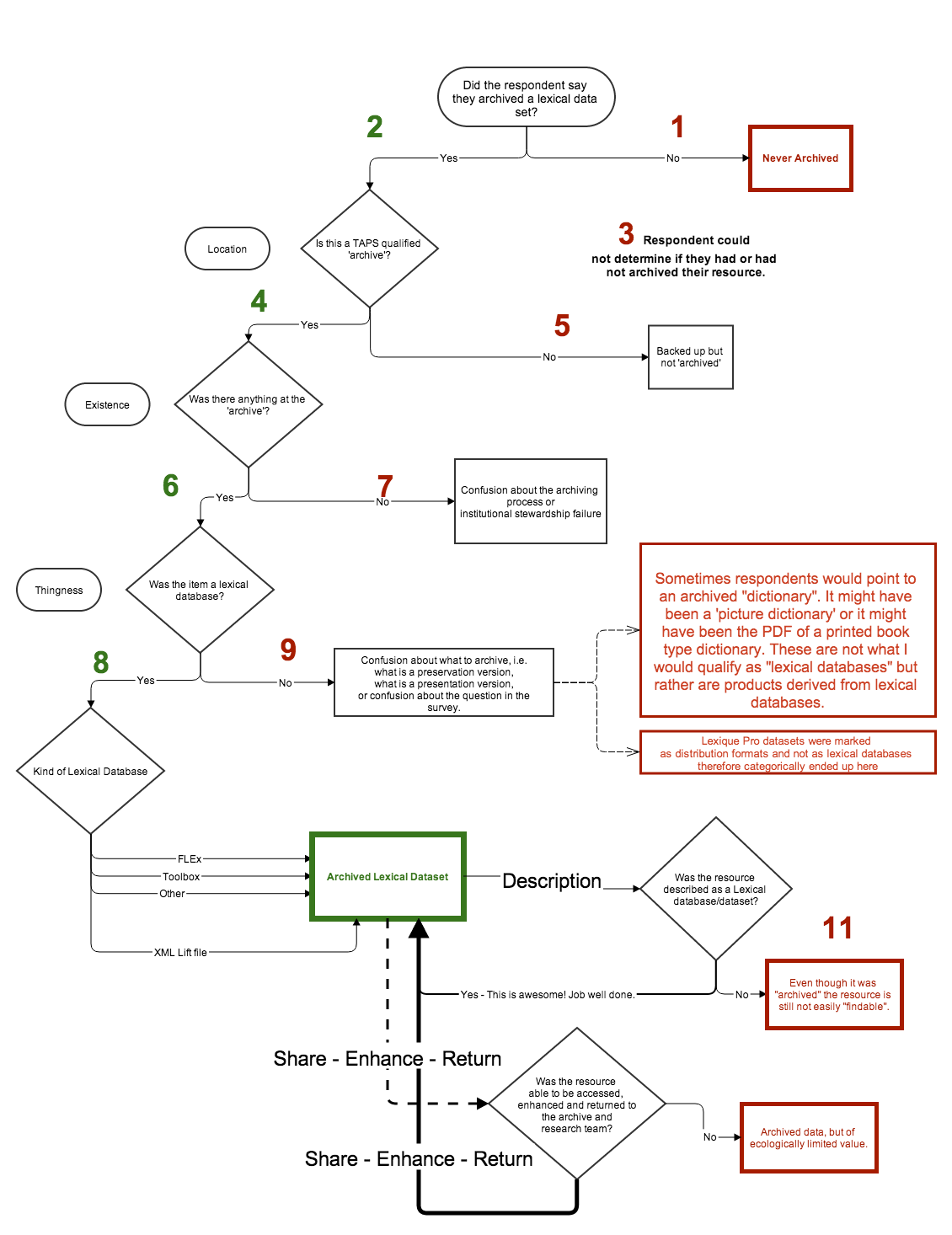
Data interpretation process
How many of these projects claim to be archived?
Items on the left are claimed to be archived, whereas the circles on the right are claimed by the respondents to not have ever been archived.
There were some cases where the respondents did not know if their lexical databases were archived.
8 Comments

Wow, there's a lot of information here!
Something to consider, when viewing how lexical databases are treated in the archive, is the capability that is baked in to FLEx 8 to automatically upload the database (lexicon, collected texts, and everything else, including possibly translated scripture) to REAP. For the sake of promoting the submission of materials to the archive, I don't think we want to discourage the use of this feature. But the observation that you make in [Section 1.2.2,](https://wiki.insitehome.org/display/~HUGH_PATERSON/2014/01/08/Archiving+Lexical+Datasets+and+Lexical+Resources#ArchivingLexicalDatasetsandLexicalResources-ArchivingLexicalDatasetsandLexicalResources-1.2.2Arethesame"Things"Equivalent?') that even FLEx databases from the same version of FLEx may contain very different data objects, makes these automatic submissions very hard to categorize. I don't have a great solution to this, I think; in a way, this automatic archiving is only slightly better than a backup solution. It doesn't seem to be very useful for data sharing, but more for data preservation. Someone could certainly use a FLEx backup to pick up a project that was abandoned by another team, or could be used by a team to recover from catastrophic loss. However, it's not the kind of resource that everyone would find useful for the same reasons, and this information cannot be gleaned from the metadata for the resource (as it is currently stored), without knowing a bit about that resource itself. (As you note, a given FLEx database may include a detailed lexicon and no texts, or it may include primary texts and anthropological observations, but not a well-articulated lexical database, and so on.)
I don't know much about how the automatic archiving flow works within FLEx 8, but this is at least something that the LCA should be working on with the FLEx developers. What information do submitters need to add to the package, in order to make is more discoverable and understandable by those who might want to access it? From your discussion here (Section 1.3.2?
 AUTHOR
AUTHORWhy would translated scripture be in a FLEx database?
As I understand it FLEx 8 only already just calls RAMP and these details are then added to the "RAMP package" however I argue that with the onion model, some data like the contributor's role and ID should be declared in the actual database architecture.
I certainly am of the opinion that FLEx databases should be their own item. However, this is not the case for how I am currently seeing them being entered into REAP, they are coming in as supporting files to other content types, like grammar sketches (SIL-PNG). In these cases they do not get their own item level description, rather they are forced into the item type of another "thing" where in my opinion I think a better model is to relate the two items with a relationship.
Hmm, okay, this is sensitive. Umm, I guess I have a friend in a sensitive entity, where a submitter is using TE in Fieldworks for drafting scripture. So, I should properly be describing these as Fieldworks backups rather than FLEx backups. When the Fieldworks auto-archive package comes in, it includes the lexical database, natural texts, and translated scripture, all together. Since it's sensitive, it would go into a sensitive collection, so no one outside the entity will ever see it, anyway, but it brings up the problem that would exist if this weren't a sensitive situation; how would you know what was in this Fieldworks database, if it wasn't somehow listed in the metadata?
And, if Fieldworks databases are coming in as supporting files to other content types, I agree that that seems odd, and that a relationship like is_derivative_of between two separate resources would make more sense. But who am I?
AUTHOR
My understanding is that TE is being phased out in favor of moving these projects to TW. So, is there even a FLEx TE version 8? But this is certainly one use case I had not thought of. It definitely needs to be added to the discussion.
What I vaguely recall hearing is that Translation Editor was being merged with Paratext, to become ParaTExt. But what that means exactly, I'm not sure. Will ParaTExt get integration with Fieldworks? Or will it still be a separate application like PT is now?
As of today, though, the landing page at fieldworks.sil.org still mentions a Bible Translation Edition with TE in it, though the download page says TE is now "minimallly supported", and that users ought to use ParaTExt instead.
And in spite of these changes, there may still be users in other places who have already been using TE, and have materials that are still in it.
- AUTHOR
A second thing here which is not discussed is the assumption about primary data. That is where is a project's primary data. Audio files, Image files, and texts. Should they be indexed, archived with FLEx databases or should these objects be archived independently as individual resources? Increasingly the FLEx user wants to integrate audio components and imagery in the context of their products. Is the place of these object in relationship to FELx (and ToolBox) as FLEx is the primary object (a bundle of 1 inclusive thing) or is the place of these things as separate, but related things which are often compiled at production time to create language resources?
- AUTHOR
An interesting question regarding database model metadata from FLEx, asked on the FLEx list.
Hi all,
[I had a few questions... was just able to figure out some of them myself (inline below), but not all.]
I've heard a little bit about FLEx having some code to cope with different S/R users having different versions of FLEx, but I'm assuming we want to avoid doing this wherever possible. We have a fairly loose-knit team, though, with both active editors and mere observers, so I'm wondering how to effectively keep track of this remotely.
Q: Is there an easy way to tell what version of FLEx (or maybe of its data model) is being used by a given repo at
languagedepot.org?A: In the Repository tab, choose to View the file FLExProject.ModelVersion. Example value: {"modelversion": 7000068}
Q: Ditto, but for an .fwbackup file? I.e. to know what's the earliest version of FLEx that can restore it. (Not that this is really a S/R question.) I do often remember to put this info in the backup comment, but there's no guarantee. (Showing this info up-front in the Restore dialog would be very nice. LT-15750)
A: Not easy, but... Change the file extension to .fwbackup.zip temporarily, and drag the .fwdata file out to copy it out. Open it in a text editor (it may be too big for Notepad, BTW; Notepad++ works great) and look at the second line or so. Example:
<languageproject version="7000068">
3. Q: Is there a way to look at either repo (server or local) and tell whether any users in recent S/R history have a version that's too old (or too new), so that the project leader can send them a friendly email?
(Note: I have TortoiseHg Workbench if that helps. But our team leader does not, so it's probably not ideal to have to go that route.)
A: ???4. If multiple users send in edits using different model versions, what will happen? Is upgrading everyone to the "highest common denominator" the best resolution?
A: ???3. Q: Is there a way to find out which FW versions correspond to each "modelversion"?
(A chart on the website would be very nice. LT-15750)A: ???Thanks,
Jon

The short answer to the question of how FLEx Bridge handles the different data model versions is that we use branches in Mercurial.
We we create the initial repo, it is in Mercurial's 'default' branch, and only one file is in that commit. Right way after that initial commit to 'default', a new branch is created the name of which is FLEx's data model version number (e'g:, 7000068) and everything is added to that new branch.
Let's use this scenario.
Everyone is using the same version of FLEx with the same data model version number of "7000068", so they are all doing S/R on that 7000068 branch.
Then one user grabs a new version of FLEx that happens to have a newer data model version number, say 7000069. That user then will do S/Rs with commits to that new 7000069, while everyone else (who haven't yet upgraded), will continue doing S/R in the 7000068 branch. [NB: There is no backwards merging of the 7000069 branch data back into the older 7000068 branch.]
As each of the other team members upgrades to the FLEx that has a data model version of 7000069, each will create their own 7000069, and the system (i.e.: Chorus) will merge that new 7000069 branch (and all of its older model changes that have been migrated to the new model) into another 7000069, if it exists.
Users on the older branch will continue sharing changes with each other, because they are on the same branch. Users on a newer branch will also share changes with each other, because they are on the same branch.
There is a nag dialogue window that comes up when there are team members on different branches. I hope it goes away, once everyone is on the same branch (data model version). :-)
I hope this answers at least some of your questions.
Randy Regnier
Oh, in case it wasn't clear.... Not every new version of Flex has had data model changes since a previous release. So, S/R users can update FLEx on their own timetable without new branches being created. Maybe that is why you want that chart of data model versions for Flex releases. We've done 68 of them so far, since FLEx 7.0 was started. 37 of them were done before Flex 7.0.somethingorother was released as stable. Not every version number contained an actual change to the data model. Many were simply fixing up data issues within the same data model. Unfortunately, the S/R branching system doesn't know there was no formal model change. AUTHOR
Per discussions here: Discussion of FLEx issues there seems to be confusion on three parts: the Archive staff, Curators, and submitters on what is a FLEx database, and how to describe its contents, and is it being archived or "backed-up" when it is put into REAP.